



AI Agent Evaluation Framework: Why It Matters for Financial Services
AI agent evaluation framework for financial services: SME-led rubrics, governance, and continuous evals to prevent production failures.
This article is a written form of a tutorial I conducted two weeks ago with Neurons Lab. If you prefer a narrative walkthrough, you can find the YouTube video here:


LLMs are often augmented with external memory via RAG architecture. Agents extend this concept to memory, reasoning, tools, answers, and actions.
Let’s begin the lecture by exploring various examples of LLM agents. While the topic is widely discussed, few are actively utilizing agents; often, what we perceive as agents are simply large language models.
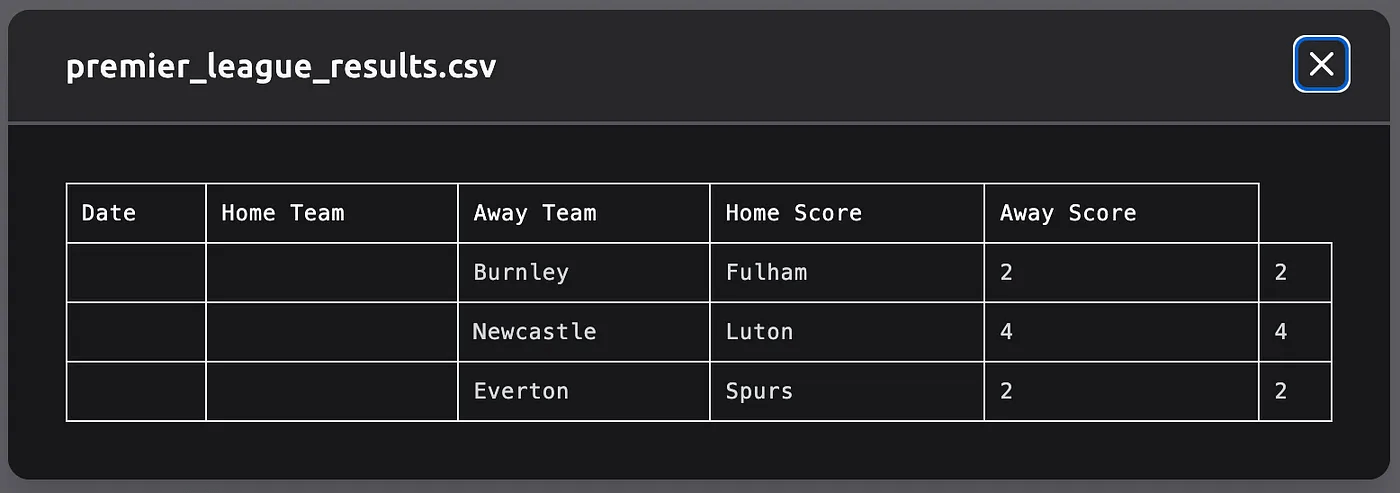
Let’s consider such a simple task as searching for football game results and saving them as a CSV file. We can compare several available tools:
Since the available tools are not great, let’s learn from the first principles of how to build agents from scratch. I am using amazing Lilian’s blog article as a structure reference but adding more examples on my own.



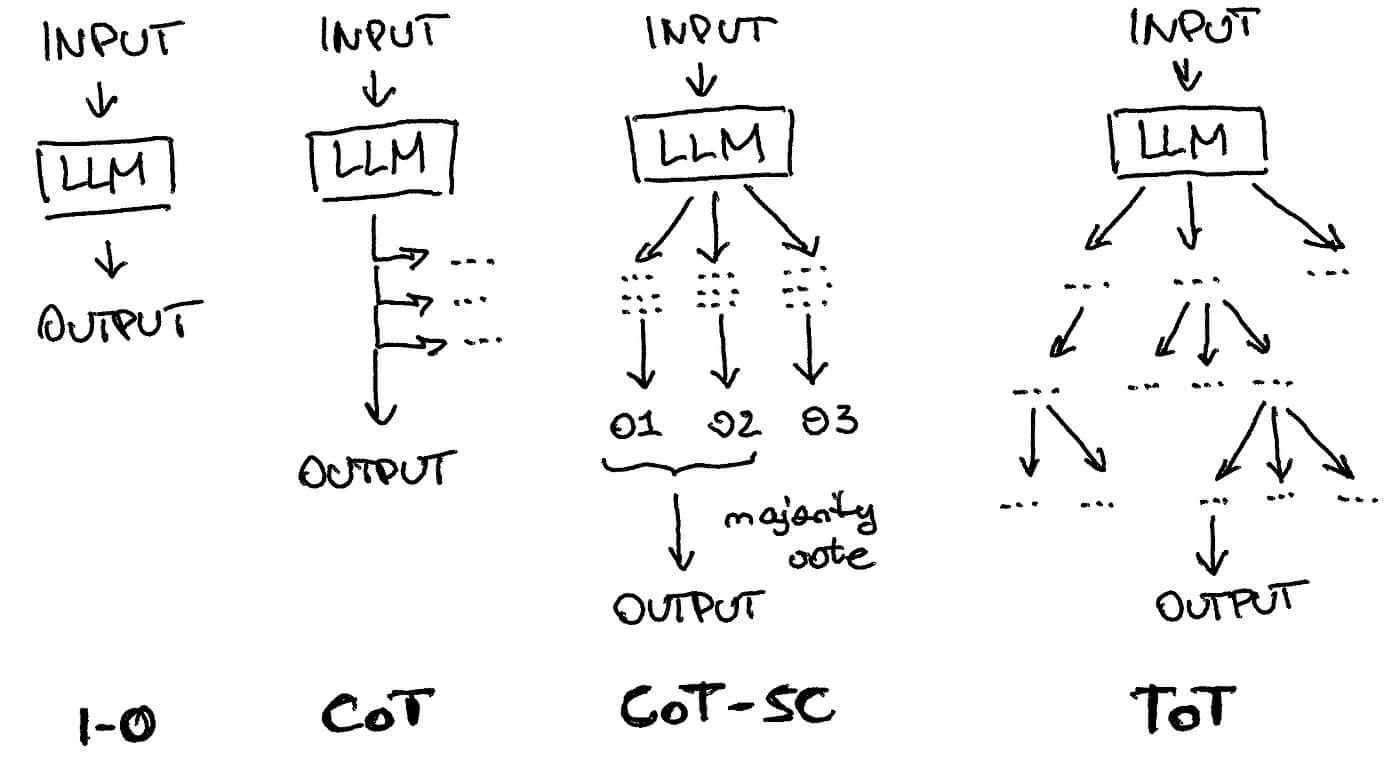
The visual difference between simple “input-output” LLM usage and such techniques as a chain of thought, a chain of thought with self-consistency, a tree of thought.
You might have come across various techniques aimed at improving the performance of large language models, such as offering tips or even jokingly threatening them.
One popular technique is called “chain of thought,” where the model is asked to think step by step, enabling self-correction. This approach has evolved into more advanced versions like the “chain of thought with self-consistency” and the generalized “tree of thoughts,” where multiple thoughts are created, re-evaluated, and consolidated to provide an output.
In this tutorial, I am using heavily Langsmith, a platform for productionizing LLM applications. For example, while building the tree of thoughts prompts, I save my sub-prompts in the prompts repository and load them:

You can see in this notebook the result of such reasoning, the point I want to make here is the right process for defining your reasoning steps and versioning them in such an LLMOps system like Langsmith. Also, you can see other examples of popular reasoning techniques in public repositories like ReAct or Self-ask with search:

Other notable approaches are:

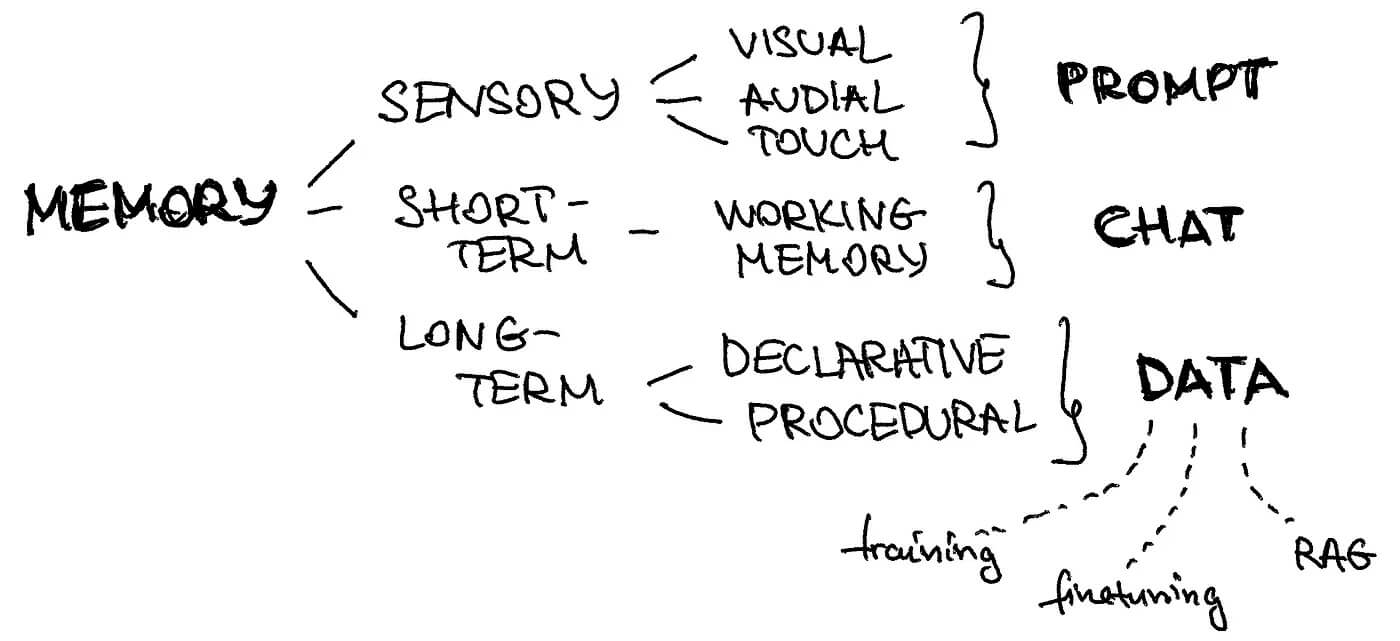
We can map different types of memories in our brain to the components of the LLM agents’ architecture.



In practice, you want to augment your agent with a separate line of reasoning (which can be another LLM, i.e. domain-specific or another ML model for image classification) or with something more rule-based or API-based.
ChatGPT Plugins and OpenAI API function calling are good examples of LLMs augmented with tool use capability working in practice.
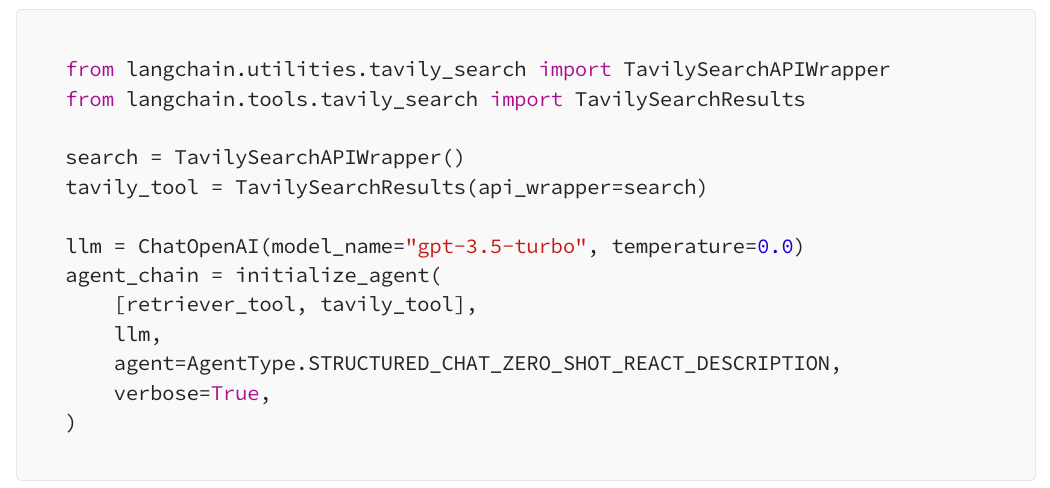
""" """ — this is how your agent will know what this tool does and will compare this description to descriptions of the other tools:
You can find examples of how it works in this script, but you also can see an error — it doesn’t pull the correct description of the Neurons Lab company and despite calling the right custom function of length calculation, the final result is wrong. Let’s try to fix it!
I am providing a clean version of combining all the pieces of architecture together in this script. Notice how we can easily decompose and define separately:
The final definition of the agent will look as simple as this:



As you can see in the outputs of the script (or you can run it yourself), it solves the issue in the previous part related to tools.
What changed? We defined a complete architecture where short-term memory plays a crucial role.
Our agent obtained message history and a sketchpad as a part of the reasoning structure, which allowed it to pull the correct website description and calculate its length.




I hope this walkthrough through the core elements of the LLM agent architecture will help you design functional bots for the cognitive tasks you aim to automate.
To complete, I would like to emphasize again the importance of having all elements of the agent in place.
As we can see, missing short-term memory or having an incomplete description of a tool can mess with the agent’s reasoning and provide incorrect answers even for very simple tasks like summary generation and its length calculation.
Good luck with your AI projects and don’t hesitate to reach out if you need help at your company!
Neurons Lab delivers AI transformation services to guide enterprises into the new era of AI. Our approach covers the complete AI spectrum, combining leadership alignment with technology integration to deliver measurable outcomes.
As an AWS Advanced Partner and GenAI competency holder, we have successfully delivered tailored AI solutions to over 100 clients, including Fortune 500 companies and governmental organizations.
AI agent evaluation framework for financial services: SME-led rubrics, governance, and continuous evals to prevent production failures.
See how wealth management firms can use AI to streamline workflows, boost client engagement, and scale AUM with compliant, tailored solutions
Discover how FSIs can move beyond stalled POCs with custom AI business solutions that meet compliance, scale fast, and deliver measurable outcomes.
See what AI training for executives that goes beyond theory looks like—banking-ready tools, competitive insights, and a 30–90 day roadmap for safe AI scale.
LLMs for finance explained: compare top models, benchmarks, costs, and governance to deploy compliant, scalable AI across financial workflows.



