

Much of the dialogue around generative AI has focussed on single-model LLMs – for example, text-based models, such as the original version of ChatGPT publicly released 18 months ago.
Earlier this month (just one day apart), OpenAI and Google changed the conversation by showcasing multimodal AI with GPT-4 Omni and Project Astra, respectively. Meanwhile, many of Amazon’s AWS AI services, such as Amazon Titan, also include multimodal capabilities.
Single or unimodal text-to-text LLMs can only analyze users’ written prompt engineering commands to provide word-form answers. However, multimodal AI is capable of both receiving prompts and providing answers using images, audio, and video, as well as text, at the same time.
As we’ll explore throughout this article, these multimodal capabilities significantly expand the already extensive range of GenAI use cases.
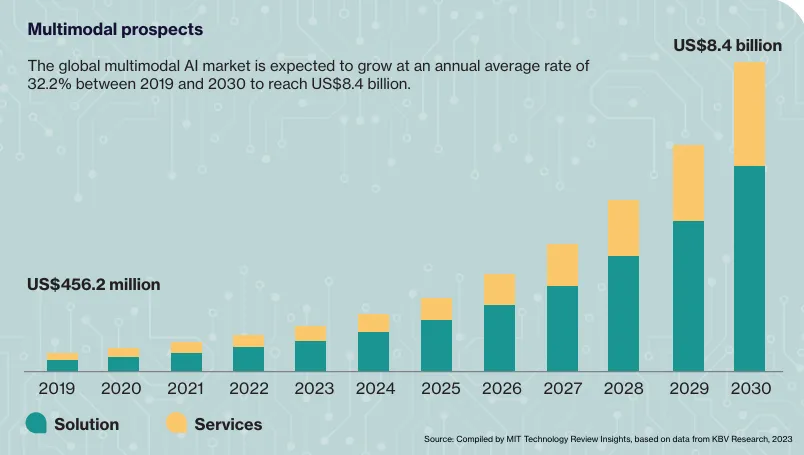
Therefore, the global multimodal AI market should grow rapidly in the coming years. According to MIT Technology Review Insights, the multimodal AI market of solutions and services could grow at an average annual rate of 32.2% until 2030, reaching an estimated total value of $8.4 billion.
Using multimodal GenAI has the potential to provide significant benefits for enterprises across all industries. It offers opportunities to improve both front-office services by improving customer experiences and back-office functions through greater operational efficiency.
Aware of the benefits, 67% of enterprise tech executives are prioritizing investments in GenAI, according to a report from Bain.

What is multimodal AI?
Multimodal AI can process and integrate information from multiple modalities or sources – such as text, images, audio, video, and other forms of data. At the core of multimodal AI are models that can process different data types or modalities.
For example, natural language processing (NLP) models handle text data, computer vision models process images and videos, and speech recognition models convert audio into text. But what makes multimodal AI unique is the ability to combine and fuse the outputs from these different models.
There are three main components:
- Input modules: Unimodal neural networks receiving and processing different data types individually – text, audio, and images, for example
- Fusion modules: These capture relevant data from each modality, integrating and aligning the information to identify the most important details
- Output modules: These produce the final results, decision, or prediction for the user based on the data processed and fused earlier in the architecture
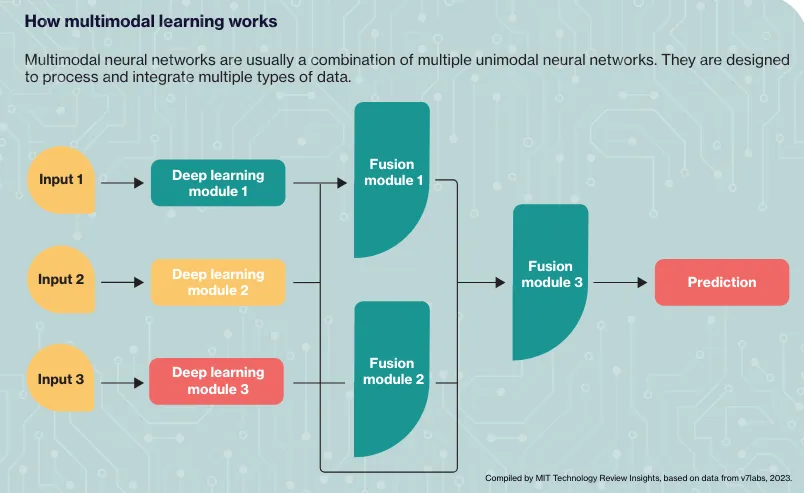
The central multimodal fusion component integrates the information from the different inputs, resolving any conflicts or ambiguities before generating a unified multimodal response.
This fusion component can combine information from different modalities using techniques such as deep learning neural networks or rule-based systems. It can also leverage contextual information to understand the user’s intent better, producing more relevant and coherent responses.
Multimodal AI use cases for enterprises
With multimodal generative AI able to process and analyze business data in different formats, there is vast potential for efficiency and cost savings throughout the supply chain. It can also optimize customer-facing operations in many ways.
Here are just a few example use cases for enterprises:
Supply chain optimization
Multimodal generative AI can optimize supply chain processes by analyzing multimodal data to provide real-time insights into inventory management, demand forecasting, and quality control.
It has the potential to optimize inventory levels by recommending ideal stock quantities based on demand forecasts, lead times, and warehouse capacities. By analyzing equipment sensor data and maintenance logs, it can also provide predictive maintenance schedules.
Improving product design
Training an LLM on manufacturing data, reports, and customer feedback can optimize the design process.
Multimodal AI can also provide predictive maintenance capabilities and analyze market trends, informing future product design.
Customer support
Simultaneously analyzing text, images, and voice data, multimodal generative AI can provide more context-aware and personalized responses, improving the customer experience.
By including visual and contextual information, multimodal AI assistants can understand and respond to customer queries in a more human way.
Marketing and sales
Multimodal LLMs can quickly co-develop dynamic marketing campaigns by integrating audio, images, video, and text.
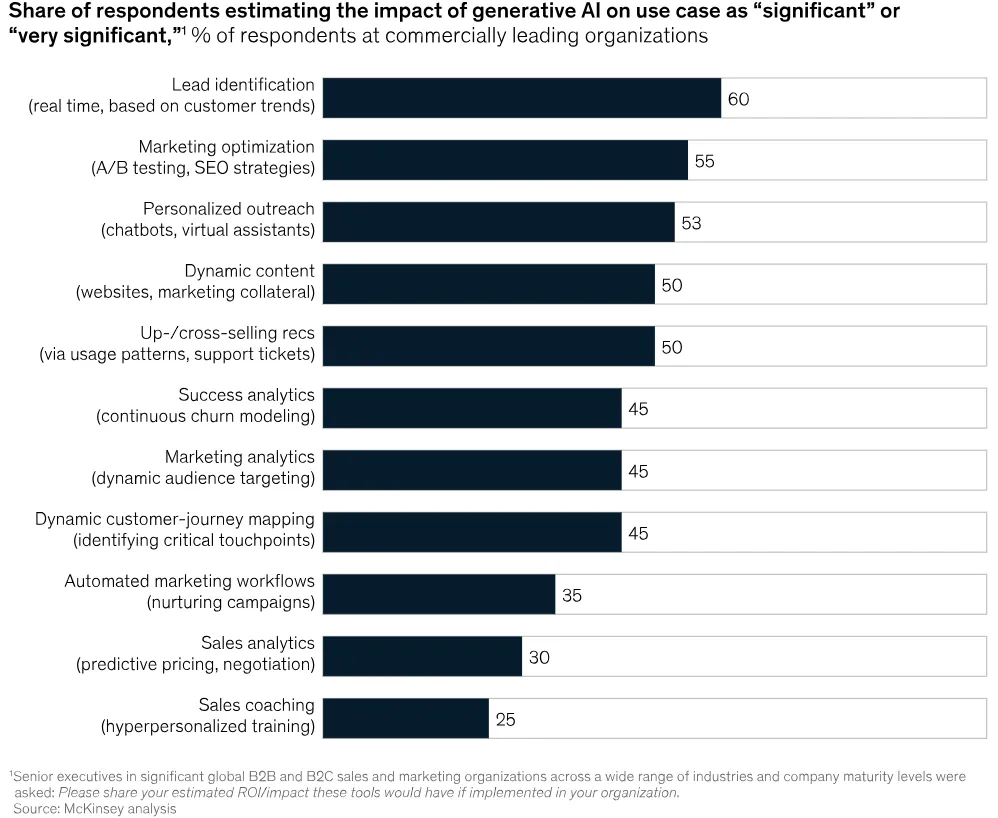
In a McKinsey survey of senior sales and marketing executives, some of the key use cases they identified for GenAI include lead identification, marketing tactic optimization and personalized outreach.
Multimodal AI use cases by industry
Here are just a few ways multimodal AI can provide benefits in different sectors:
Healthcare
By combining medical images with patient records and genetic data, healthcare providers can gain a more accurate understanding of a patient’s health.
This offers the potential to more efficiently tailor treatment plans to individual patients based on multiple data sources.
GenAI can reduce the administrative burden for healthcare professionals in many ways, leading to more time spent with patients and better outcomes. Find out how Intelligent Document Processing (IDP) helped Treatline reduce time spent on administration by 70%.
Financial services
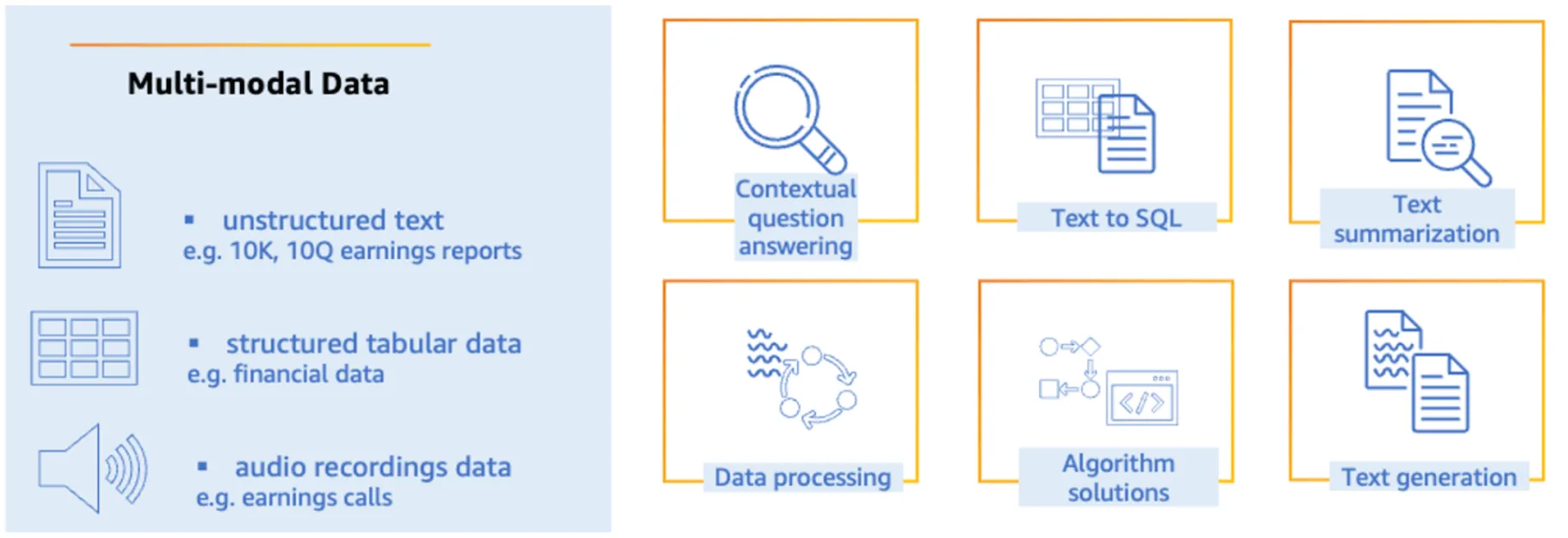
Multimodal AI can feature in solutions that:
- Interact with customers by analyzing voice, text, and visual inputs – providing personalized advice, answering queries, and assisting with account management
- Analyze various data sources such as transaction records, user behavior patterns, biometric data (including voice or facial recognition), and social media activity to detect and prevent fraudulent activities
- Process audio data from earnings calls, analyst meetings, and news broadcasts for insights around company performance and market sentiment, integrating this information with text and financial data to support informed trading decisions
- Extract relevant information from financial documents containing text, tables, charts, and images (including annual reports or contracts) to automate and improve analysis tasks
In a recent AWS Machine Learning Blog post, a team of experts explored this in detail.
Retail
In retail, use cases include letting customers interact with an LLM through voice, text, and images to receive personalized product recommendations and assistance with purchases.
By combining customer data (including purchase history, preferences, and browsing behavior) with multimedia content (such as product images and videos), multimodal LLMs can generate product recommendations and highly personalized marketing campaigns.
Manufacturing
In manufacturing, multimodal AI use cases include:
- Analyzing camera images and videos from production lines plus sensor and product data to detect defects, anomalies, or quality issues in real-time
- Incorporating data from sensors, operational logs, and audio signals (such as unexpected noises or vibrations), multimodal AI can predict equipment issues and recommend predictive maintenance, reducing downtime and extending its lifespan
- Providing real-time advice, instructions, and alerts based on visual, audio, and sensor data from production
Advantages of leveraging multimodal generative AI
Potential benefits include:
- Better customer experiences: A key advantage of multimodal over single-modal generative AI is its potential to provide more natural and intuitive interactions between humans and LLMs.
- Higher accuracy: By taking information inputs in several formats, multimodal AI can achieve higher accuracy compared to unimodal LLMs.
- Greater resource efficiency: By focusing on the most relevant information from each input, models can learn how to limit the amount of irrelevant data to process.
- More transparency: Multimodal AI can provide different sources of information to explain its system’s output. Not only does this make the outputs easier to interpret, but by more clearly explaining the reasons behind answers, there is greater accountability.
Overall, multimodal LLMs have the means to provide unprecedented efficiency for enterprises by significantly streamlining work and empowering better resource allocation.
Challenges
While these are manageable, considerable expertise is required to address the following challenges when using multimodal AI.
- Data Volume: Multimodal AI handles much more data from a broader range of inputs, which can be challenging to manage.
- Complexity: Strong hardware and very advanced algorithms are required to process and analyze different data formats simultaneously and make complex decisions.
- Missing data: Missing data across different input formats presents additional challenges to multimodal AI accuracy.
Final thoughts
Multimodal generative AI has the potential to provide major benefits for enterprises across all industries.
It provides opportunities to optimize front-office services by improving customer experiences and offering unprecedented personalization. There is a direct link to revenue here – companies with the best customer experience bring in 5.7 times more revenue than others, according to Forbes.
Multimodal generative AI can also transform back office functions through greater operational efficiency, optimizing costs.
These benefits align closely with the main focuses of enterprises’ GenAI initiatives, based on a recent Gartner survey:
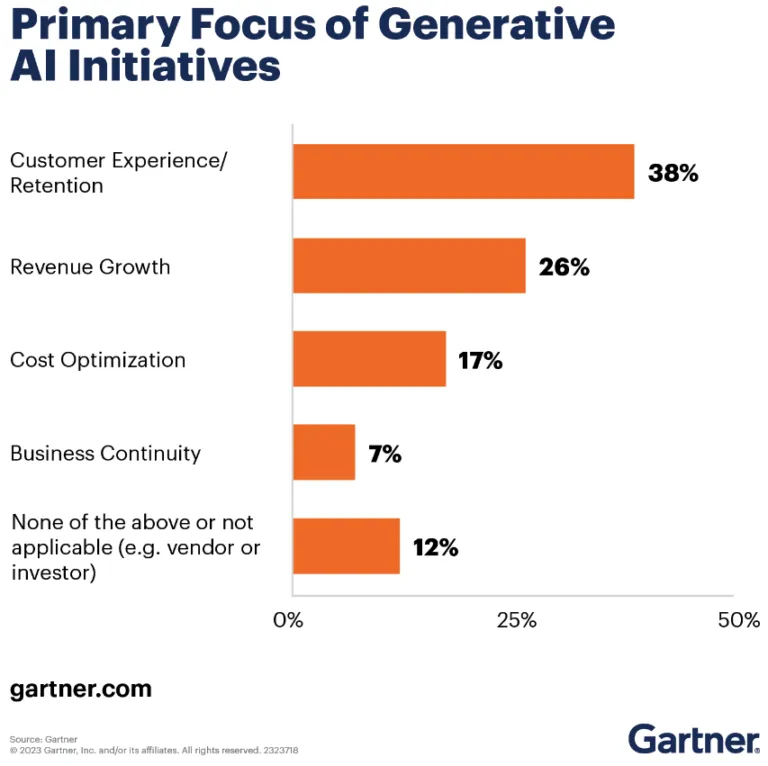
How to explore your use cases for multimodal GenAI
Multimodal generative AI has a wide range of use cases, but each business and its sector will have a different specific area with the highest likely return on investment.
This could involve automating and accelerating operations or delivering cutting-edge personalization and experiences to customers.
If you’re not sure how to get started, Neurons Lab can help. With our GenAI Workshop and Proof of Concept service, 75-100% funded by AWS, we turn your ideas into detailed strategies and tactics. We build a working proof of concept to validate assumptions and reduce risk when investing in GenAI technology.
To discuss how we can help you gain a competitive edge with GenAI, please get in touch.
About us: Neurons Lab
Neurons Lab delivers AI transformation services to guide enterprises into the new era of AI. Our approach covers the complete AI spectrum, combining leadership alignment with technology integration to deliver measurable outcomes.
As an AWS Advanced Partner and GenAI competency holder, we have successfully delivered tailored AI solutions to over 100 clients, including Fortune 500 companies and governmental organizations.




