



What is the Cost of AI for BFSIs in 2026? 4 Examples To Budget Accordingly
Here is how banks, insurers, and fintechs can budget for AI with scenarios and cost drivers—subscriptions, overages, infrastructure, and ownership
Even the best AI pilots that work in a sandbox can still fail in production. Why? Because traditional user acceptance testing (UAT) was built for API-driven software, not LLM-orchestrated agentic AI systems.
So, once your AI project moves from a testing environment to your core financial workflows you become vulnerable to operational, compliance, and reputational risks that you didn’t plan for in your proof of concept stage.
AI evaluation frameworks designed for financial services can help.
At Neurons Lab, we specialize in helping financial institutions modernize their operations using AI. Based on our experience delivering over 100 AI projects across highly regulated industries, we’ve seen that AI project evaluations reduce these risks as well as do much more.
In this article:
Want to move beyond outdated testing methods to an evals framework that sets you up for long term AI success? Neurons Lab can help. Book a call with us today.
Old methods like UAT and sandbox testing are poorly suited to modern AI systems. That’s because these systems aren’t binary like software that ‘works’ or ‘doesn’t work’. Agentic AI systems are made up of many interacting parts whose behavior changes depending on context and datasets.
For example, what looks like a simple AI assistant or banking chatbot is actually a network of agents—one of several possible agent architectures—that orchestrates complex workflows, such as:
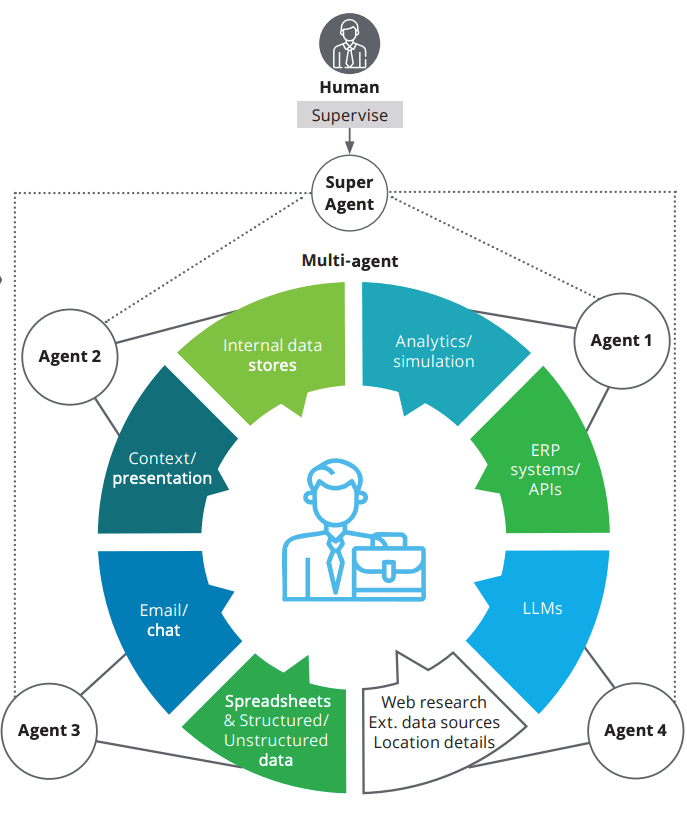
One-off testing at launch can’t cover this behavior. AI evaluations (AI evals) ensure these systems are monitored early and continuously with observability so they perform consistently, even as models, data, and context change.
AI evals are structured tests that measure how a model performs in real-world conditions to support debugging and improve agent performance quickly. They matter, especially in financial services, because they turn unpredictable, non-binary AI behavior and agent’s responses into measurable, auditable performance.
Evals enable financial firms to prove their agentic AI system is accurate, compliant, and safe beyond a one-time sandbox or UAT pass. It’s the complexity of these systems that requires a different way of measuring success. That’s because:
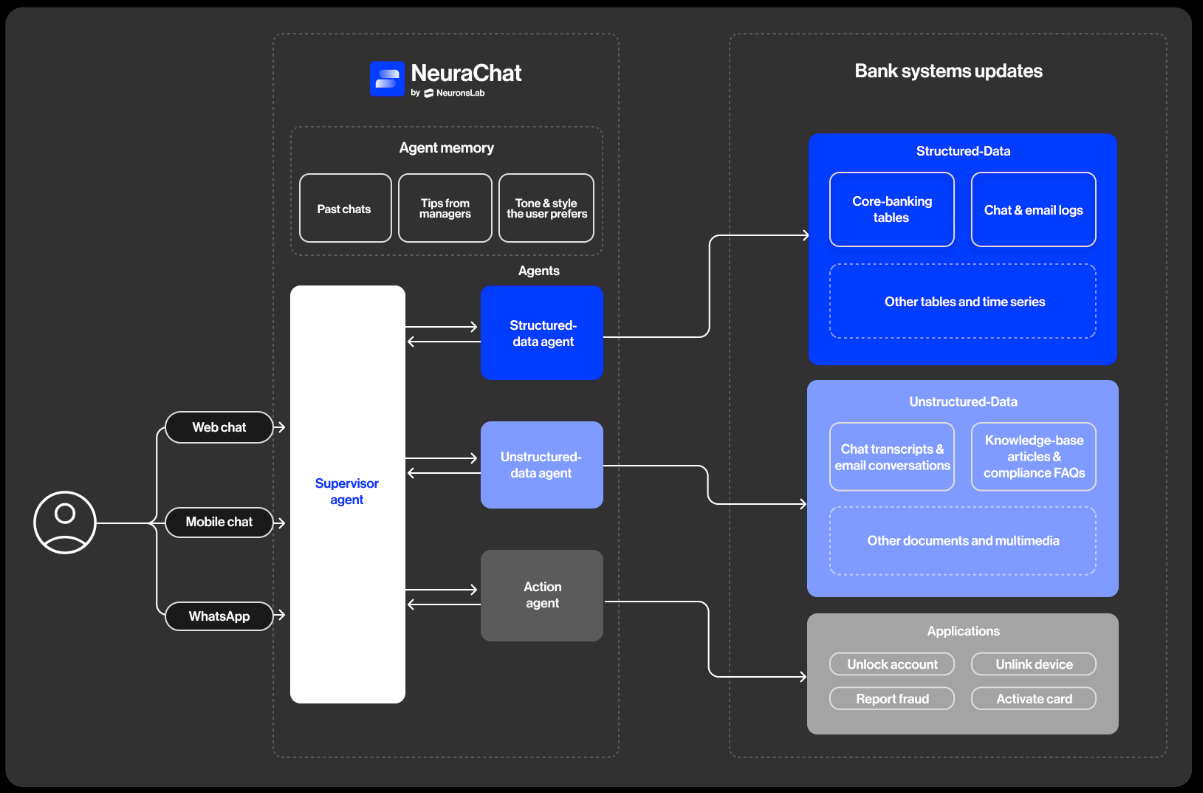
If you’re investing in agentic AI, evals are what protect your investment. They do this by preventing hidden failures, proving compliance, and enabling confident rollout.
In the next section we’ll show you how to design an evals framework that delivers that control.
Here’s how to create an evals framework for your bank, insurance or financial services firm:
The first step to successful evals is determining which processes you want to support with AI for each use case. That’s because you can’t evaluate an agent until you’ve defined the workflow and whether the work is actually suitable for agentic AI or better handled by RPA.
For example, if you plan to augment your workflows with agentic AI, McKinsey research states that high variance and low standardization processes are the best fit. These are workflows where each case is different and there are few rigid rules or fixed paths. This gives the agent room to decide how to act, adapt to context, and add value.
Low-variance, highly standardized work, such as routine data entry, is often better handled with traditional automation like Robotic Process Automation (RPA). Once these processes are clearly defined, evals can measure whether your AI agent is behaving correctly within them.
Next, define the skills your AI needs. For an agentic AI system, this is what agents ‘should do’ and ‘how they should behave’ according to experts, not vendor assumptions.
Defining skills is what makes evaluation possible because it turns ‘behave well’ into observable behaviors, expected outputs and task completion. As such, your subject matter experts (SMEs) must be deeply involved from the beginning to describe not only the process but also the required context, edge cases, and expected outputs as we mentioned earlier.
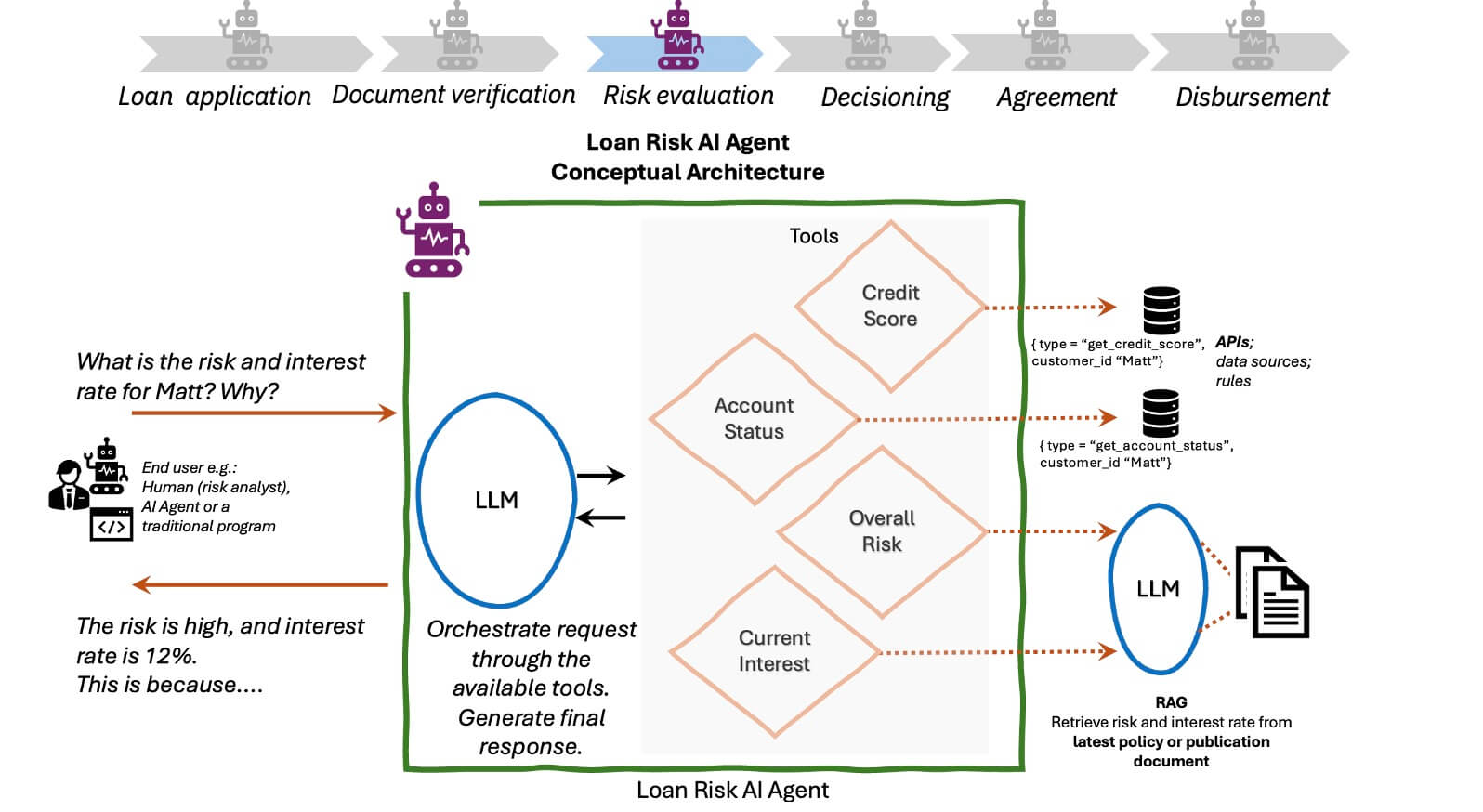
Resolved and ideal cases, often referred to as ‘silver sets’ and ‘gold sets’, evaluate how AI behaves in real workflows. They also assess whether large language model (LLM) reasoning aligns with SME expectations.
Silver sets are built from real processes completed by experts such as:
Each represents a complete unit of work with a clear start and end, even if it passed through several departments. You likely have many of these, and to use them for your evals, your SMEs will need to review and label them. They must then explain why these cases were handled well or poorly to help define how your AI agent is expected to behave.
Golden sets are highly curated cases created from scratch by your SMEs. They define what good, average, and bad AI agent behavior looks like. For example, they can show how a loan application should be handled or how a support ticket should be resolved, and what actions to avoid.
Together, silver and gold sets give you a clear benchmark of test cases and ground truth for measuring if your AI system is behaving correctly. That way, you can identify gaps, fix issues and keep agent performance consistent over time.
As we previously mentioned, context engineering includes structured, unstructured and procedural guidance. Agentic systems perform poorly when they are given too much data at once.
Instead of loading an agent with all the relevant domain knowledge, rules and edge cases upfront, introduce context gradually and only at the right point it’s needed in the workflow. This sequencing, also known as context engineering, is best led by your SMEs. They understand the actual workflows and can define what information is needed, when it is needed, and how it should be used.
Evaluation should begin early in the project phase and continue throughout day-to-day operations, as models, context, and integrations change. This helps set up the context and guardrails before launch. It also avoids treating sandbox testing as the final or only check.
Start by evaluating processes internally at the context level with SMEs, such as investment analysts or relationship managers. Their input defines the rubrics used to assess AI behavior, typically grouped into two categories: subjective and objective.
Both subjective and technical evaluations (and the evaluation results) create a complete, controllable framework for measuring and improving AI performance over time.
Evaluations should also account for governance requirements to prove decisions are traceable and compliant. This includes audit trail completeness, policy compliance checks, and if human review occurred when required.
For example, in financial services, compliance regulations increasingly require every decision to be traceable and explainable. Whether it’s a loan approval, insurance claim or reimbursement, your AI audit trail shows how the decision was made.
For ongoing governance, monitor:
Flows, context and internal systems can change. New regulations can also be introduced. As such, it’s risky to keep evaluations a one time exercise. A model that performs well at launch can drift over time due to these changes, creating poor outputs, regression, and regulatory risk.
Instead, set a defined cadence for AI evaluation, such as per release, per model or context change, along with a recurring review cycle so you can iterate safely. This includes monitoring technical parameters and keeping SMEs involved to review outputs, edge cases, and drift over time. This ensures you catch issues early and keep your AI systems reliable, compliant, and effective.
If your AI evaluations rely solely on generic metrics or technical benchmarks, you can miss critical business context. And this can lead to AI outputs that fail to reflect real workflows. Your subject matter experts provide this missing foundation.
Here’s why your SMEs are key to AI evals for financial services:
SMEs like relationship managers in a wealth management firm understand how client interactions unfold, which market insights to consider first, and how conservative or proactive a recommendation should be. They can define what should never be suggested and set the guardrails AI must follow.
This is what makes SMEs uniquely positioned to provide the necessary context AI systems need to produce relevant outputs. Context forms a semantic layer on top of raw data, including internal policies, standard operating procedures, and domain expertise.
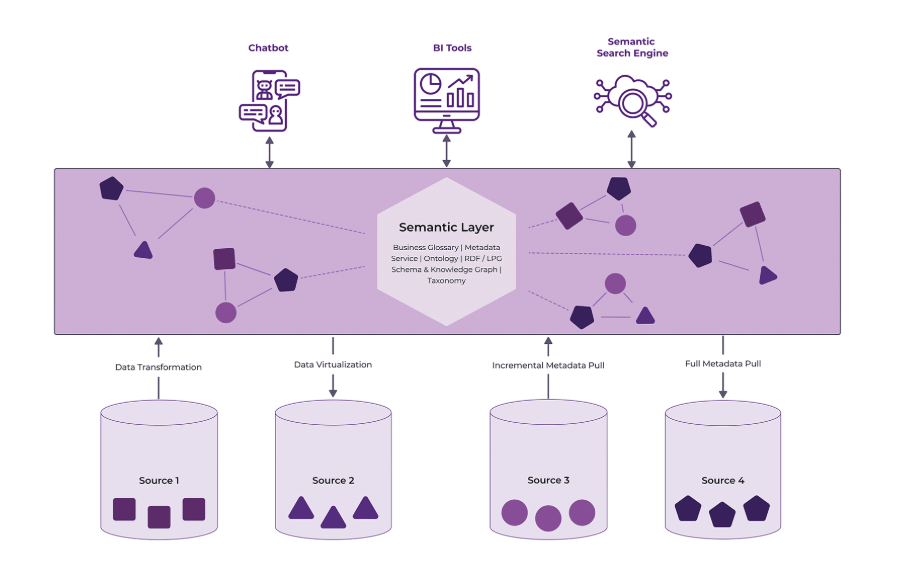
It explains why certain information is relevant and how different data sources relate to each other, whether structured (like databases) or unstructured (like market reports). Context is also unique to each BFSI. So even if wealth management appears similar across organizations, each one uses this context differently. And these differences directly influence AI outputs, shape the service customers receive, and become a key source of differentiation.
SMEs also help decide when different context should be injected into the workflow to ensure AI stays accurate and reliable. Flooding the AI with too much data all at once can lead to agents being overloaded and unable to focus on the right information. This can cause it to hallucinate or apply the wrong logic. For example, when given an insurance client’s entire 15 year history and multiple policies at once, an AI agent taking over a claim might skip critical steps or apply the wrong rules.
Financial services workflows are complex and multi-step, involving multiple systems, approvals, and decision points. When embedding AI, these processes often have to change to account for new agentic skills or elements.
For example, workflows shift from slow human-led tasks to faster human-in-the loop processes. So, instead of doing manual customer research across five different systems, a relationship manager can simply prompt an AI assistant to receive an instant client summary.
Because SMEs understand these workflows best, they can re-engineer and evaluate them in their new state. In a wealth management context, for example, this would require coordinated effort across different experts like business, IT, risk and compliance teams:
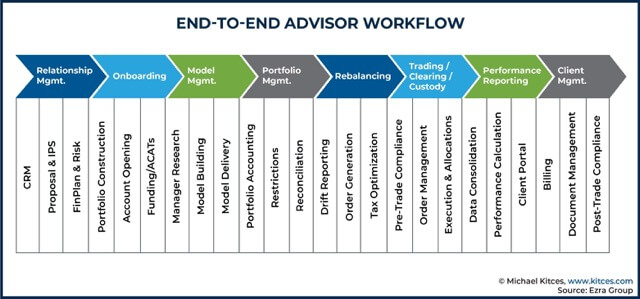
SMEs know how work actually gets done, so they can define what good AI behavior looks like in practice. They do this in three key ways:
By letting your SMEs define what good looks like, you can measure AI agent performance against your own operational standards, rather than generic evaluation metrics. This ensures AI behaves as your experts would in real workflows.
SMEs have valuable tacit knowledge that is often difficult to document or transfer. However, their involvement in evaluating AI agents means that they translate their knowhow and judgment into clear evaluation metrics.
For example, since SMEs define exactly what makes a high-quality customer presentation or successful meeting preparation, this can be embedded into your AI systems.
So, even if a star relationship manager leaves your organization, their specific knowledge and standards remain within the evaluation framework. This creates a new form of long-term value by ensuring that you capture and retain critical expertise.
With Neurons Lab, you can set up evals that keep AI performing accurately and reliably over time.
Neurons Lab is a UK and Singapore-based Agentic AI consultancy serving financial institutions across North America, Europe, and Asia.
As an AI enablement partner, we design, build, and implement agentic AI solutions tailored for mid-to-large BFSIs operating in highly regulated environments, including banks, insurers, and wealth management firms. Trusted by 100+ clients, such as HSBC, Visa, and AXA, we co-create agentic systems that run in production and scale across your organization.
Here’s how we help you design and implement evals that ensure AI success:
Choosing the right SMEs and defining clear evaluation criteria doesn’t have to be complex. With deep financial services expertise, we understand how different roles, such as relationship managers, financial analysts, or underwriters, operate in practice and how their judgment translates into AI behavior. This helps you identify which SMEs should be involved and where their input matters most.
Through our training and education services, your SMEs and teams will understand why context matters, how it can be measured, which inputs are needed, and which evaluations to run. That way, they move beyond vague feedback and define clear, actionable evaluation criteria.
Because you gain clarity early in the process, you’ll test sooner, get results faster, and be confident that your AI systems behave as intended while meeting strict standards for quality and reliability. Over time, as we collaborate to build evaluation frameworks and transfer knowledge, your teams will develop the capability to run and refine AI evals independently.

To support your evals, you need the right data and infrastructure foundations. As we’re an AI system integrator, you’ll have the expert backing you need to create a solid data foundation and technical infrastructure that can handle all the complex technical aspects of evals.
This includes embedding the context defined by your SMEs so AI behavior is consistent, and aligned with real workflows. We then implement the integrations that supply this context, so your agents retrieve the right information from the right systems.
Our expertise in multi-agent orchestration, deterministic tool calling, and retrieval approaches such as RAG, and knowledge graphs mean you’ll have the AI architecture to support complex multi-step workflows.
And with governance, guardrails, and audit trails built in from the start, your AI systems remain continuously evaluable, secure, and compliant.
Evals help BFSIs manage the variability and complexity of AI systems while ensuring they continue to perform even as workflows, data, and regulations evolve. By embedding subject matter expertise, firm-specific context, and clear evaluation criteria, AI systems can reflect how firms actually operate and deliver value to customers. This moves them beyond the limitations of generic AI solutions and sets them apart from competitors.
Realizing these benefits typically requires support beyond internal capabilities. An experienced AI partner with financial services expertise like Neurons Lab can help you define evaluation frameworks with your subject matter experts, embed context correctly, and implement the technical foundations needed to support continuous evaluation.
If you’d like to explore how AI evals can support compliant differentiated AI in your organization, book a call with us today.
Sources:
Here is how banks, insurers, and fintechs can budget for AI with scenarios and cost drivers—subscriptions, overages, infrastructure, and ownership
See how wealth management firms can use AI to streamline workflows, boost client engagement, and scale AUM with compliant, tailored solutions
Discover how FSIs can move beyond stalled POCs with custom AI business solutions that meet compliance, scale fast, and deliver measurable outcomes.
See what AI training for executives that goes beyond theory looks like—banking-ready tools, competitive insights, and a 30–90 day roadmap for safe AI scale.
LLMs for finance explained: compare top models, benchmarks, costs, and governance to deploy compliant, scalable AI across financial workflows.



