

In this article, based on a webinar I conducted recently, I provide an overview of how to build an AI Cloud engineer capable of writing, testing, and executing code. This is particularly useful for engineers who write code daily, but it can be easily adapted to other use cases.

For example, it applies to:
- Developers who are looking to adopt a solution that can handle workloads more efficiently.
- Software engineers who want to make their company’s services more cost-efficient, leveraging the AI Cloud engineer to support developers.
- Cloud engineers who need to provide more efficient Cloud migration services. For example, you can upload a diagram, write a description, and then the AI will generate code for you.
However, this solution is not just for code generation. It can generate various artifacts, such as marketing materials, reports, and more.
What is a RAG state machine?
Here is a range of potential options for using retrieval augmented generation (RAG).
In the below diagram, there is a question, an index database, and a large language model (LLM) – this diagram shows a linear process:

The user asks a question, the system checks the index database, generates a response using the LLM, and provides the answer.
However, in the next diagram, a router provides more choices:
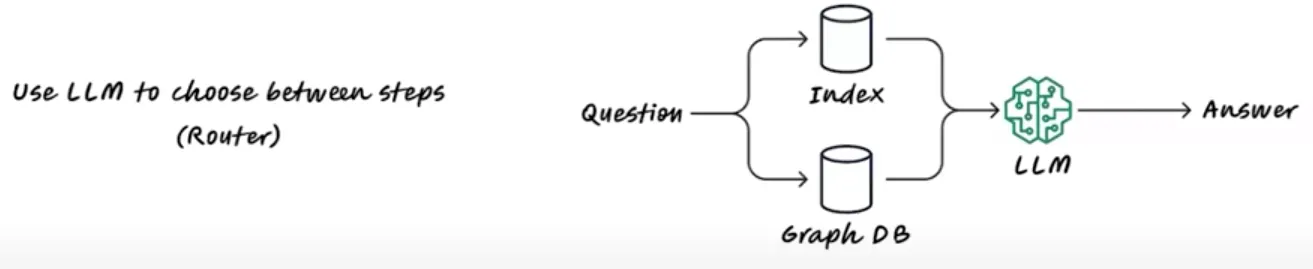
Let’s say we have a question. Based on this, we can use the index database or some other resources and tools to add logic to the application.
However, this version has no cycles or feedback loops – it is still quite linear. Therefore, this third option features an improvement that makes the solution very useful for code generation:

Imagine you have written some code and tried to run it, but it fails. The next step is to look for the error on Google Search, find an answer, fix the code, try again, and so on.
For many, this is the standard coding experience. It’s very repetitive and can be highly frustrating.
This is where an AI solution leveraging a state machine can be a game-changer. A state machine allows you to distinguish business logic from execution.
After generating and testing the code, you can implement a feedback loop to rewrite it. For example, if you encounter an error, you send it back to the RAG system to regenerate the code based on the feedback.
Let’s take another perspective – here is a classic RAG chain:
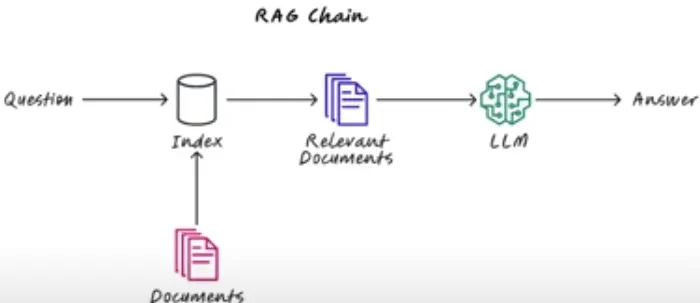
Like the previous diagrams, we start with a question, and the RAG finds the relevant information—in this case, from a document database— to generate the answer.
Here’s how a RAG state machine can improve the process:
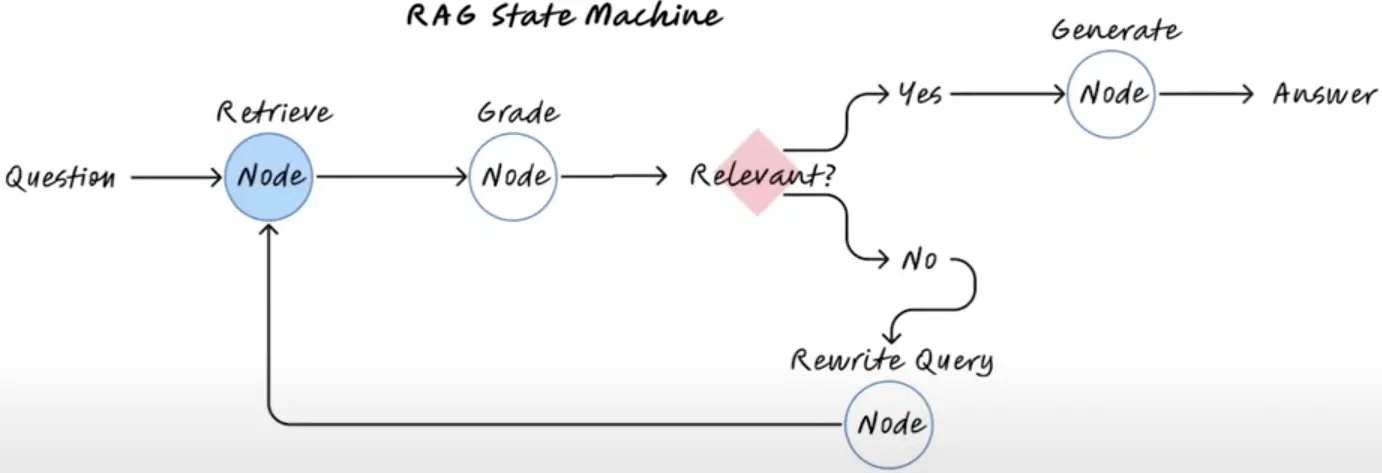
In the above diagram, after receiving the documents, you can score them based on relevancy.
You can check if the documents are relevant to your question. If they are not, you can rewrite the query, creating a feedback loop to ultimately retrieve more relevant documentation.
The process repeats until you have the most relevant documentation, at which point you run a generation node to get the answer. This is how state machines can significantly improve the quality of RAG systems.
The different options for generating code using a LLM
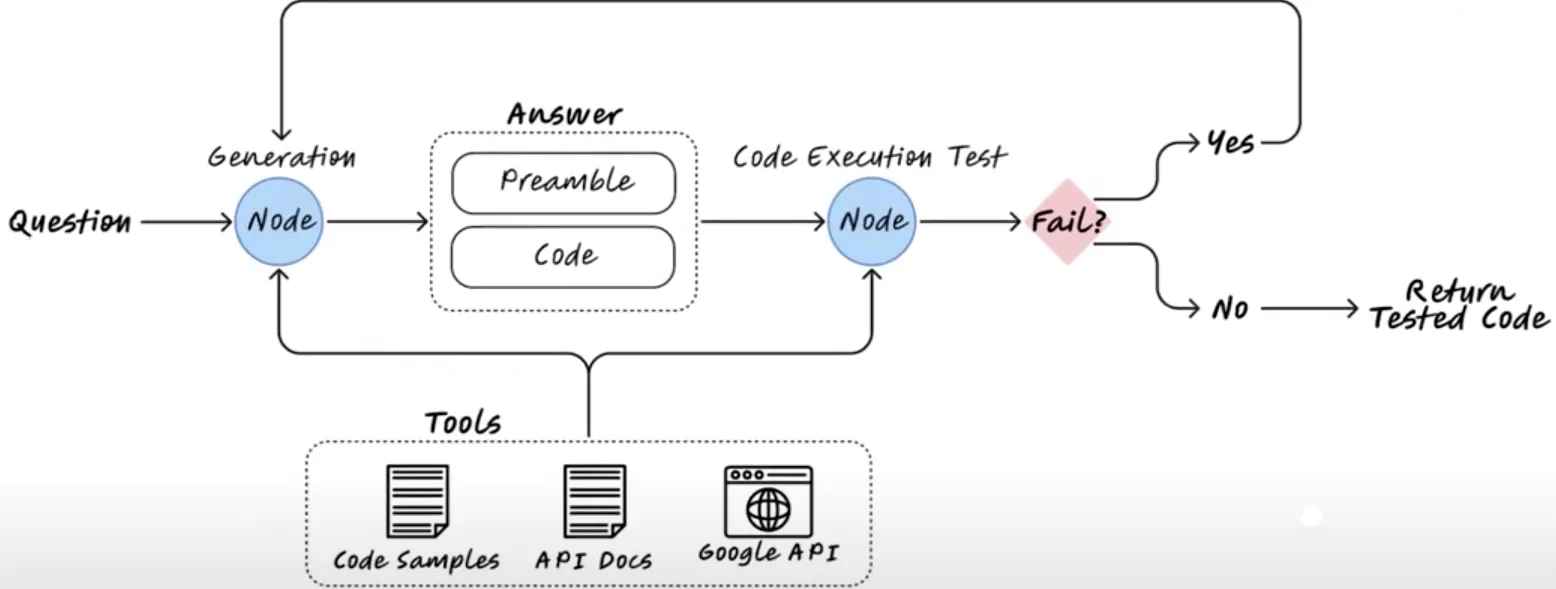
This diagram shows LangChain technology and how to implement a RAG state machine.
As before, we start with a question. The system generates some AWS Cloud Development Kit (CDK) code, which you receive alongside a description as the answer – this state is stored in the graph.
Then, you would try executing this code. But if you have just started development, usually during this execution, it will often fail.
If it fails, the system captures this feedback—the error—and returns to retrying the code generation. This process repeats until you reach maximum retries or generate a working code.
With this solution, you can also integrate tools such as API documentation or a Google API and attach code samples. There is a lot of potential for optimizing this system, too.
To summarize everything so far, here is a table showing the different options for involving a LLM in code generation:
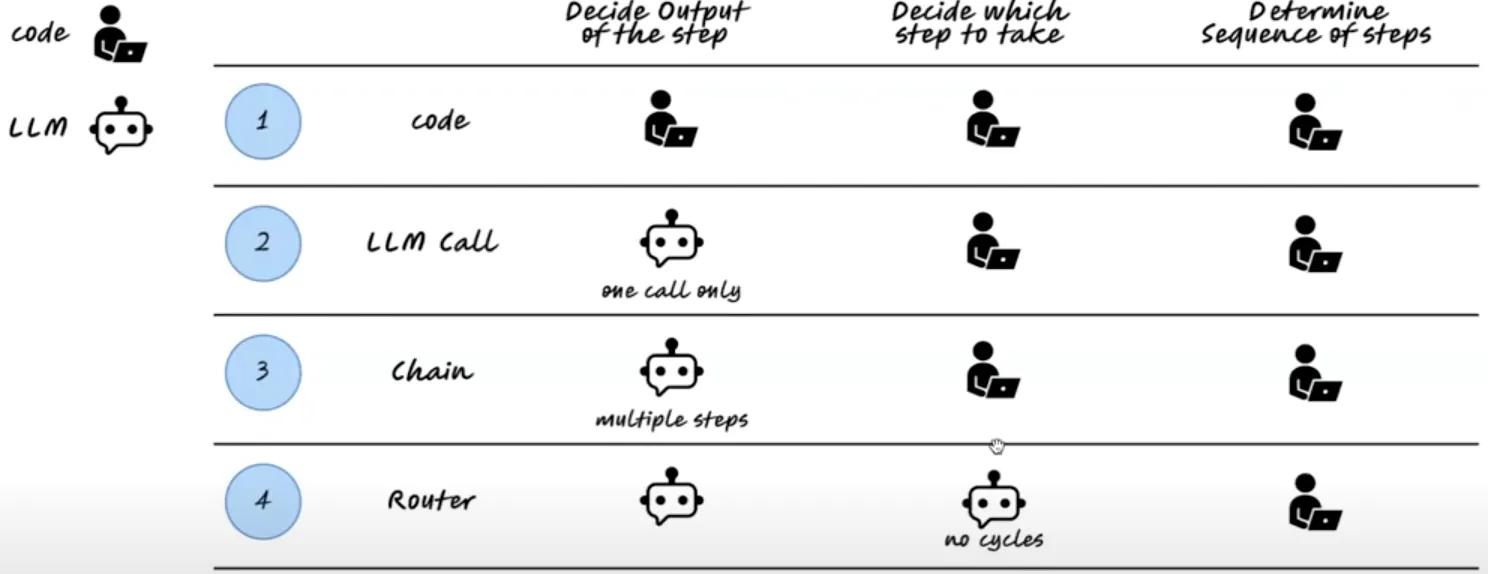

- Option 1 is the default process of writing all the code yourself – deciding on outputs, which steps to take, and the right sequence.
- Option 2 uses an LLM, but with one call only, you perform the remaining steps yourself.
- Option 3 with chains lets you perform multiple steps with the LLM.
- Option 4 lets the LLM decide which step to take but includes no cycles.
- Option 5 uses a state machine – the LLM decides which steps to take and accommodates feedback via cycles.
In addition, Option 6 is a full end-to-end agent that is potentially capable of deciding on outputs, which steps to take, and the right sequence. Currently, agents are not yet ready to do this accurately for code generation, so state machines give much more advanced outputs.
Building an AI engineer
For a full step-by-step walkthrough of how to build an AI engineer using a state machine with LangGraph and Anthropic Claude 3, check out my interactive demonstration from [13.30] onwards.
In this section, I share a few highlights. First, this is some of the code for the first class node:
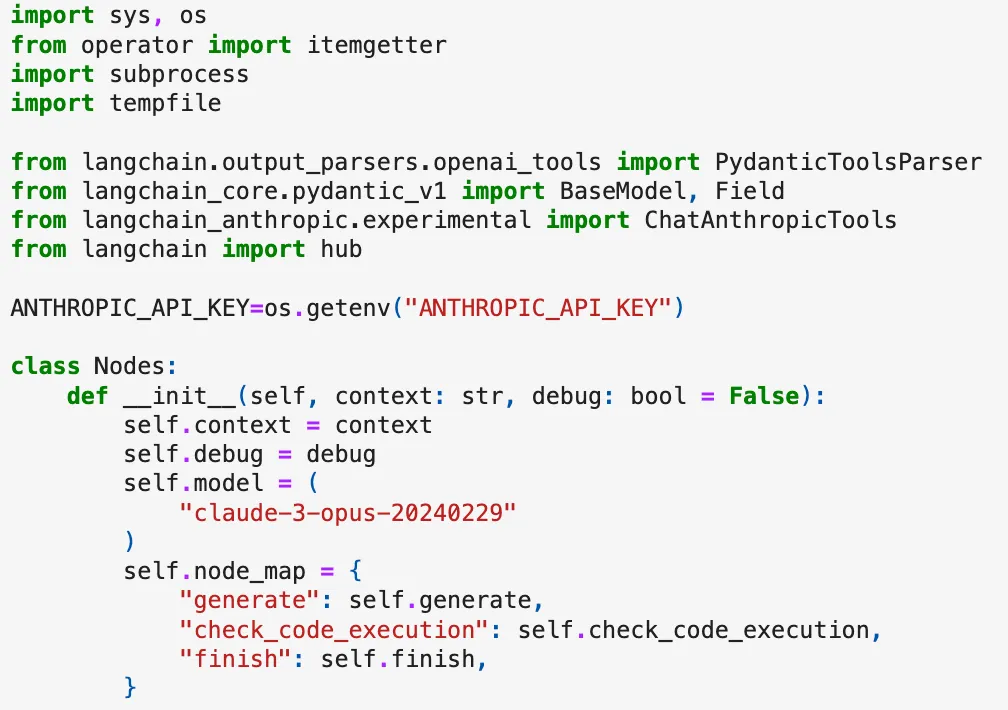
Later it includes a process to capture errors and outputs as part of a feedback loop. If the initial code generated fails, the system captures the error.
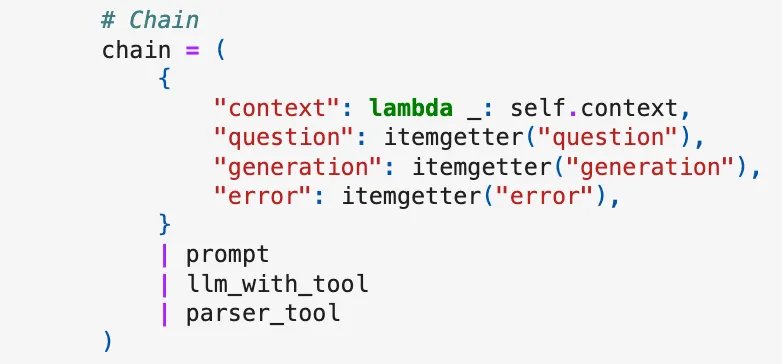
Edges connect the different nodes. This code contains instructions on how to generate and check the code execution.

Again, if generated without errors, it will finish, but if there are errors, it will regenerate the code.

And here is the code for the agent, the knowledge graph used for document retrieval.
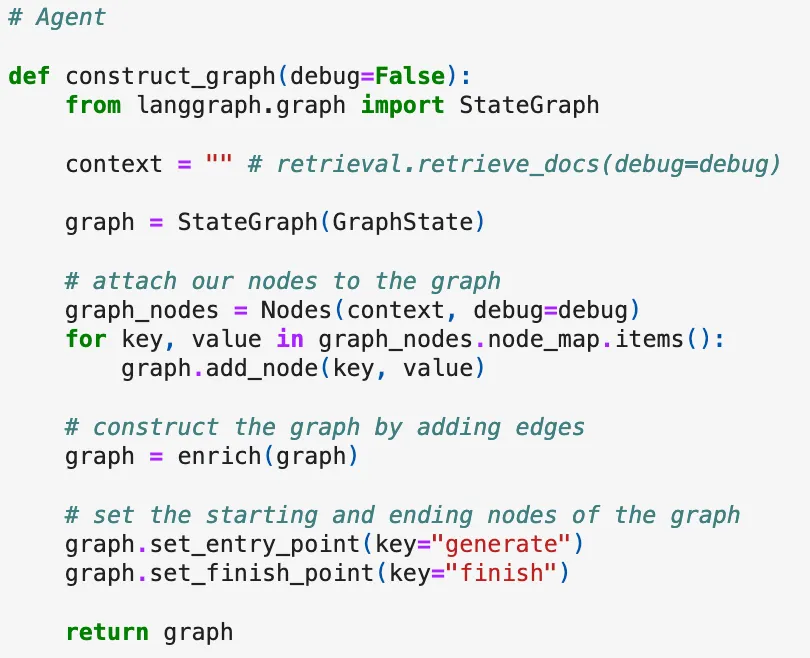
The model works quite well without context – but if you wish to provide relevant context, you will need to do additional steps: gather documentation, create embeddings, and store it in a vector store.

I have used LangServe for the API to connect the solution and trigger the response. LangServe allows for easy integration between the API and the LangChain graph.

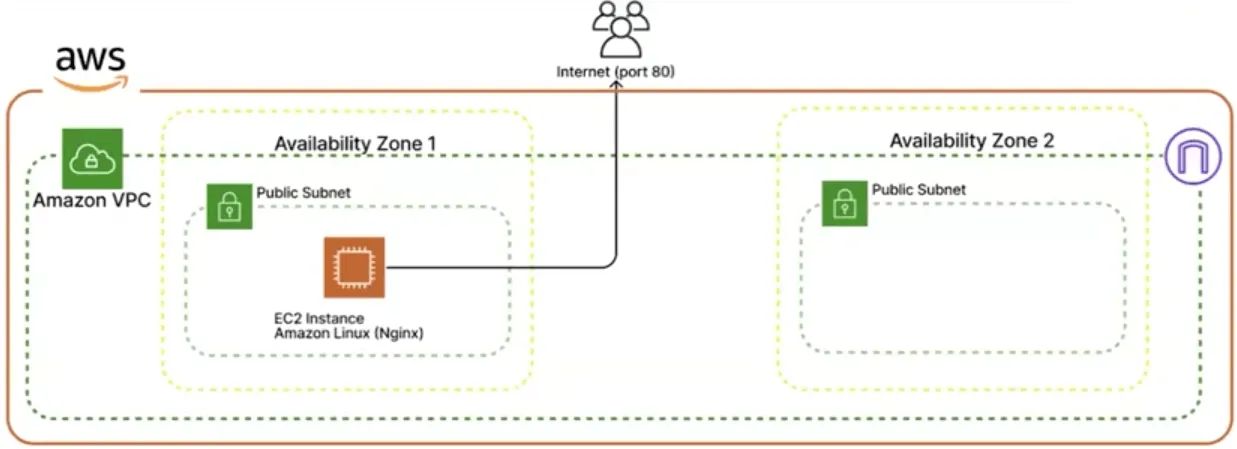
We often include AWS architecture diagrams in our documentation, and this is a very useful input.
Instead of writing the description yourself, you can put your architecture diagram into Claude3, and it will generate a description.
Here is the response from Claude 3:

Conclusions and next steps
To improve the solution in the long term, we would need to run more tests in an isolated environment.
This demo version shown in part above does not yet capture all the errors.
For a more complex solution, instead of trying to create the whole application through one script, I would recommend splitting it. Rather than uploading a big diagram, dividing it into iterations, going step by step, executing, testing, and then deploying it would be preferable.
Security testing is critical. I would also recommend commanding the solution to use SSL encryption in transit, and then, I would need to see security tests according to best practices. That may highlight extra errors in the code to fix.
About us: Neurons Lab
Neurons Lab delivers AI transformation services to guide enterprises into the new era of AI. Our approach covers the complete AI spectrum, combining leadership alignment with technology integration to deliver measurable outcomes.
As an AWS Advanced Partner and GenAI competency holder, we have successfully delivered tailored AI solutions to over 100 clients, including Fortune 500 companies and governmental organizations.




