



AI for Retail Banking: Use Cases + How to Get Started
Learn how retail banks use AI agents to automate workflows, improve customer experience, and scale operations with measurable results.
If you’re researching the best LLMs for finance and financial analysis, you’re likely looking to implement AI across your firm to achieve business outcomes like greater efficiency and productivity. But in choosing your financial LLMs, you may be uncertain about:
As an AI enablement partner with over 100 AI projects delivered across financial services, we can help you navigate these decisions. To understand the different models and what to consider for your AI implementation, we’ll cover:
Want to integrate custom AI solutions powered by LLMs across your operations for measurable results? Get in touch with us now.
Large language models (LLMs) are a type of natural language processing (NLP) system trained to predict and generate text based on input prompts. They power everything from banking chatbots to AI assistants and can reason, summarize, and act when integrated with external tools. In the table below, we compare the key differences, capabilities, and use cases each model is suited for.
Note: The table and list below summarize model families and typical strengths, but they should not be treated as a ranking. Selection should be based on evaluation against your workflows, cost constraints, and governance requirements. See the benchmarking section for performance evidence and limitations.
| Model | Capabilities | Reasoning | Cost and Speed | Ideal Financial Use Cases |
|---|---|---|---|---|
| OpenAI 5 Series | Data analysis, search, image generation (via tools), agents and tool orchestration | Deep multi-step reasoning with strong planning | Highest cost. Can be slower when deep reasoning is used. | Complex synthesis, financial document analysis, strategic planning, multi-step workflows, copilots, agent tool use, forecasting, and complex calculations linked to internal systems and market data |
| OpenAI o-Series | Data analysis, search, image generation, and deep research (e.g., o3-deep-research / o4-mini-deep-research) | Specialized, deliberate multi-step reasoning with high precision | Medium to high cost, moderate speed for one-off analysis | Complex document comparison, contract and case-file analysis, multi-step financial workflows such as KYC, onboarding, and complex control and risk assessments |
| OpenAI 4 Series | Data analysis, search, image generation, and fast instruction following and tool calling (non-reasoning) | Moderate to good reasoning for standard tasks | Medium to very low cost, with very fast speeds for mini and nano | Real-time chat, customer support, advisor assist tools, multi-document workflow processing, large-scale summarization, and high-volume enterprise use |
| Google 2.0 series (Gemini 2) | Multimodal models with tiered options (Flash, Flash-Lite, Pro) | Flash prioritizes speed; Pro supports more complex prompts | Flash and Flash-Lite are optimized for speed and cost efficiency; Pro is heavier | High-volume summarization and extraction, document intake and routing, operational analysis, and customer support use cases |
| Google 3.0 Series (Gemini 3) | Advanced multimodal models designed for agent-style workflows | Stronger reasoning for multi-step tasks and tool use | Varies by tier; Flash emphasizes lower latency | Multi-step workflows that require tool use, complex analysis across multiple documents, and agent-based automation |
| MetaAI Llama 4 series | Multimodal, multilingual models available for self-hosted deployment | General-purpose reasoning, typically paired with retrieval | Cost and speed depend on deployment and infrastructure | Internal assistants over proprietary documents, RAG-based knowledge base Q&A, and controlled environments requiring self-hosting |
| Anthropic Sonnet 4 series | Text and image input; general-purpose enterprise model | Balanced reasoning for everyday workflows | Designed to balance capability, speed, and cost | Analyst assist, summarization, drafting and review, policy Q&A with retrieval, and workflow copilots |
| Anthropic Opus 4 series | Text and image input; highest-capability Claude tier | Strong sustained, multi-step reasoning | Higher cost; used where depth matters more than latency | Complex document synthesis, investigation-style analysis, and multi-step agent workflows with human oversight |

The GPT 4.1 series, which includes GPT 4.1, GPT 4.1 mini, and GPT 4.1 nano, is the smartest non-reasoning family. It is optimized for high-volume enterprise use, offering good problem-solving for everyday tasks with fast, low-latency responses. This means it excels at real-time chat, customer support, advisor-assist tools, and large-scale summarization.
The evolution of GPT models – Image source: OpenAI

Image source: OpenAI
The o models, which includes o3 and o4 mini, is designed to think step by step before providing an answer. This makes it ideal for complex reasoning tasks that require precision and more explainable outputs (summaries) when prompted, including multi-step financial workflows, such as KYC, onboarding, contract analysis, document comparison, and complex risk and control assessments.
The o series deep research capability is powered by dedicated deep research variants (o3-deep-research / o4-mini-deep-research) designed to run multi-step research workflows with search and synthesis.
Image source: OpenAI
The most powerful of the OpenAI models is the GPT 5 series, which includes GPT 5, GPT 5.1, GPT 5.2, GPT-5 mini / GPT-5 nano and GPT-5.2 pro. It is the most advanced and reliable model family for writing, research, coding, and problem-solving.
These models deliver higher quality responses through deep reasoning, multi-step logic, and strong planning abilities, making them well-suited for complex use cases such as copilots, agent tool use, and advanced research tasks.
This series can accelerate your financial reporting, financial planning and analysis (FP&A), and insight generation through structured analysis, web search, and agent mode connectors. It can further support accurate financial forecasts, cash flow forecasting, valuation work, and complex calculations by linking to your internal systems and market data. These models also offer enterprise privacy controls, and business data is not used for training by default.

The Gemini 2 series includes 2.0, 2.0 Flash Thinking, 2.0 Pro and 2.0 Flash-Lite and is built for fast, scalable, multimodal work (text plus other inputs, depending on the endpoint). In finance settings they’re typically a good fit for high-volume tasks like summarization, intake triage, and first-pass extraction from documents where throughput and cost control matter more than deep multi-step reasoning. Google positions Flash as the fast general option, Flash-Lite as the lower-cost high-throughput option, and Pro for more complex prompts.
This series includes 3.0 Pro, 3.0 Flash, 3.0 Deep Think and Gemini Agent.
Considered Google’s more capable family for stronger reasoning and agent-style workflows, Gemini 3 can be a better choice when you need the model to follow multi-step instructions, use tools reliably, and handle more complex analysis than “summarize and extract.” Pro is the higher-capability tier, while Flash emphasizes speed with strong capability.
This series’ multimodal capabilities are available only in specific Gemini APIs and products, not universally.
The Llama 4 series includes Scout and Maverick with Behemoth coming soon.
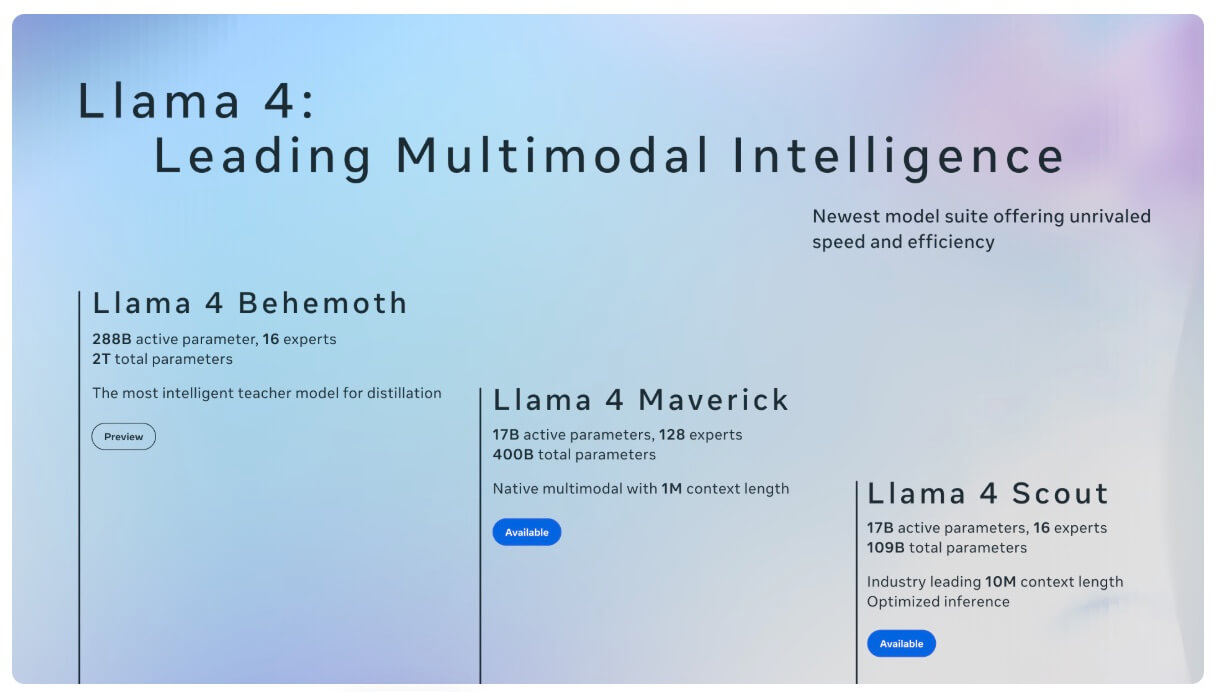
Llama 4 can be a good option when you want more control over how a model is deployed, including the ability to run it in your own infrastructure. This can be useful for internal assistants that work over large sets of proprietary documents.
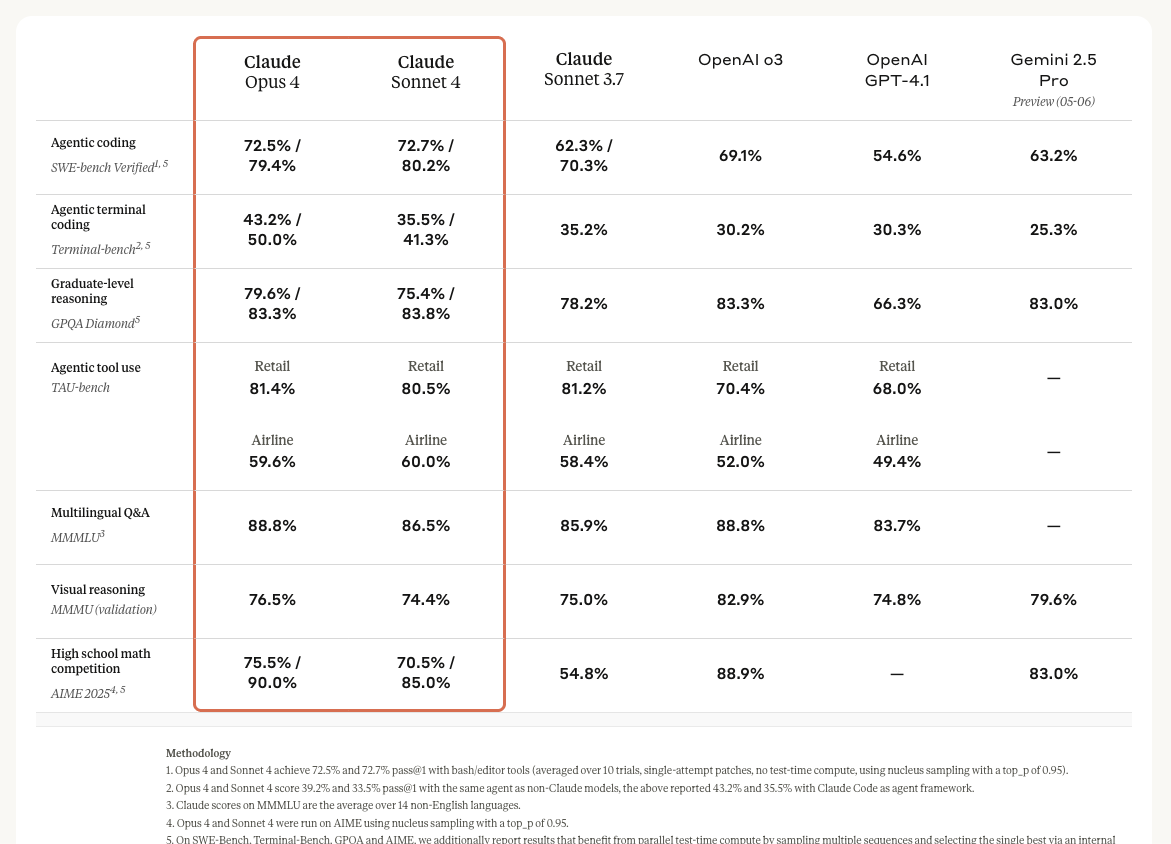
Anthropic’s benchmarking of its Claude Sonnet and Opus 4 series – Image source: Anthropic
This series offers strong capability for everyday work while being more cost-efficient than top-tier models. In finance workflows, it’s commonly used for drafting, summarization, policy/Q&A (with retrieval), and analyst support where you want reliable instruction-following without paying for the most expensive tier.
Anthropic positions this Claude 4 model as more suited to harder reasoning and longer, more complex tasks. This can be useful when you’re doing multi-step document synthesis, deeper analysis, or more demanding agent workflows (still with human review and auditability in regulated contexts).
To understand how well today’s large language models actually perform on financial tasks, we reviewed several widely cited benchmarking studies. While the methodologies differ, the results are consistent: current LLMs can support finance teams, but they still struggle with accuracy, tool use, and complex reasoning, particularly in enterprise settings.
FinanceBench is one of the most thorough evaluations of LLMs on real financial questions. The study tested 16 leading models using 10,231 finance-specific questions grounded in publicly available materials such as SEC 10-Ks, 10-Qs, 8-Ks, earnings reports, and earnings call transcripts.
The overall conclusion? Existing LLMs have clear limitations for financial question-answering. Even when paired with retrieval systems, models frequently produced incorrect answers or refused to answer altogether. In fact, GPT-4-Turbo combined with retrieval failed in 81% of cases, and Llama 2 showed the same failure rate under similar conditions.
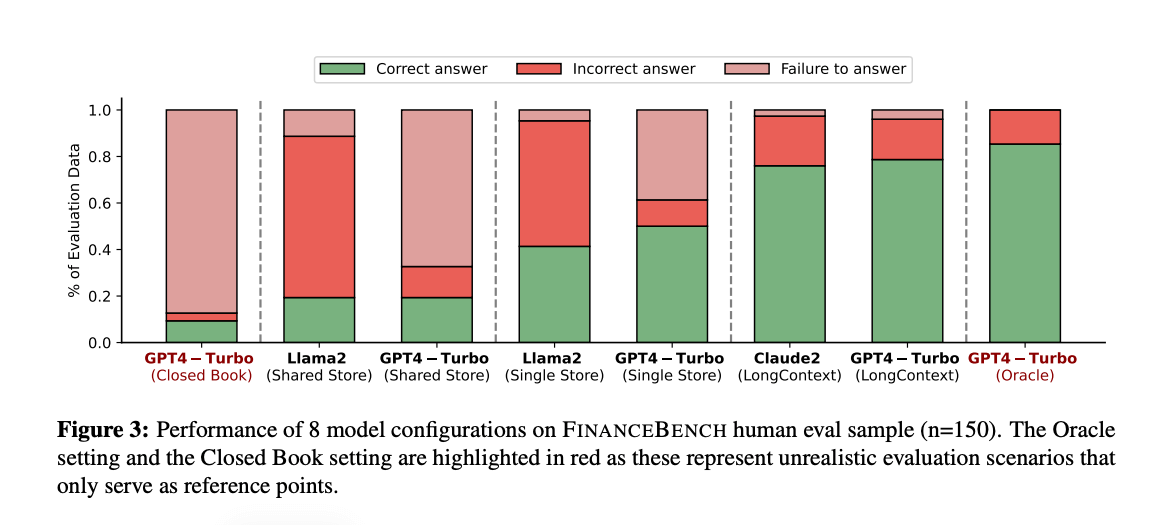
Image source: FinanceBench
The researchers also tested long-context approaches, where large volumes of source material are passed directly into the model instead of retrieved dynamically. While this improved results somewhat, failure rates were still significant—21% for GPT-4-Turbo and 24% for Claude-2—and the authors noted that these approaches are often impractical in enterprise environments due to latency, cost, and document size constraints.

Image source: Finance Bench
Across all setups, the study found recurring issues with hallucinations and inconsistency, reinforcing the need for strong controls and validation when using LLMs in financial workflows.
AI Multiple focused specifically on financial reasoning. The benchmark evaluated 30 models using 238 difficult questions that required multi-step quantitative reasoning with financial concepts and formulas.
In this study, the strongest performers were GPT-5 (gpt-5-2025-08-07) and GPT-5-mini, which achieved the highest accuracy overall. Claude Opus 4.1 stood out for offering a strong balance between accuracy and efficiency, delivering competitive performance while using fewer tokens.
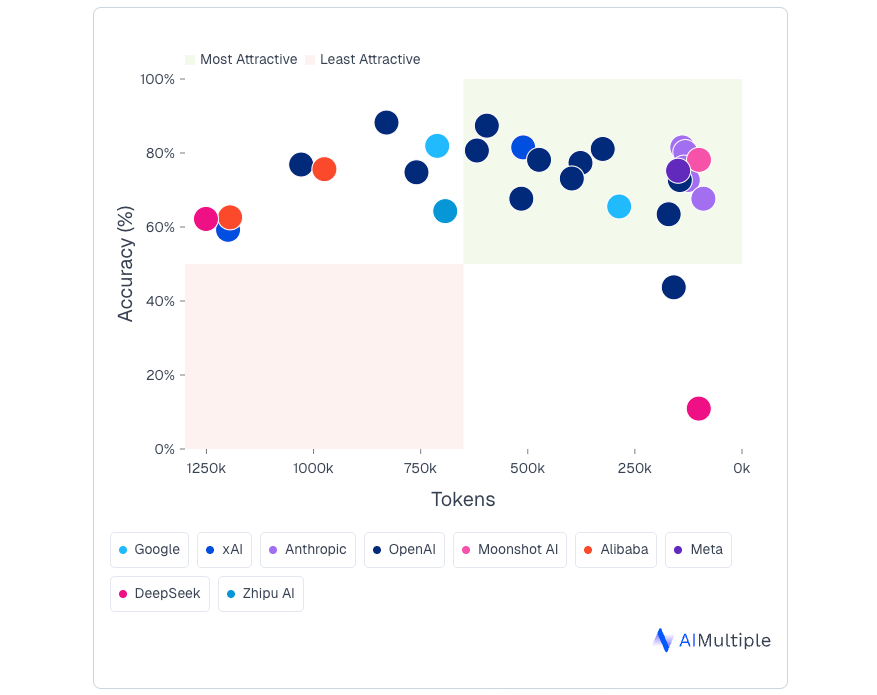
Image source: AI Multiple
Other notable performers included Gemini-2.5-Pro and Claude-Opus-4. One interesting finding was that there was no clear relationship between how many tokens a model used and how accurate it was—suggesting that “thinking longer” does not automatically translate into better financial reasoning.
Vals.AI evaluated 57 models using 537 questions designed to test whether AI agents can handle tasks expected of an entry-level financial analyst. These tasks ranged from simple retrieval and qualitative analysis to market research and projections, including work that required examining SEC filings.
On this benchmark, GPT-5.1 ranked first on the Finance Agent leaderboard with 56.55% accuracy, followed closely by Claude Sonnet 4.5 (Thinking) at 55.32%.
The results highlighted a recurring challenge across models: tool use. Many models struggled to reliably retrieve information from external sources, which led directly to incorrect answers. On average, models performed best on straightforward quantitative and qualitative retrieval tasks—work that is relatively easy but time-consuming for human analysts.
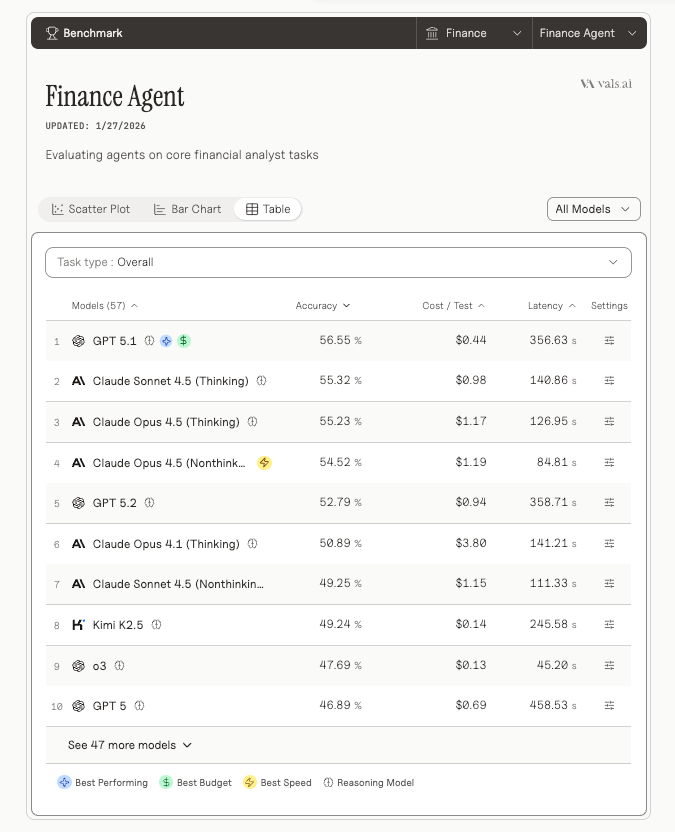
Image source: Vals AI
FinGAIA took a different approach by comparing model outputs directly against human performance. The benchmark tested 10 models (9 closed-sourced models and 1 open-sourced model) across 407 finance-related tasks spanning securities, funds, banking, insurance, futures, trusts, and asset management.

Image source: FinGAIA
ChatGPT (DeepResearch) achieved the highest overall accuracy in this evaluation, but its performance still lagged behind experienced human experts. This was particularly evident in strategic risk scenarios, where AI performance was generally weak. The study also found that market forecasting and fraud detection remain difficult areas for most models, with ChatGPT showing comparatively stronger results in fraud detection but still achieving only 39.0% accuracy.
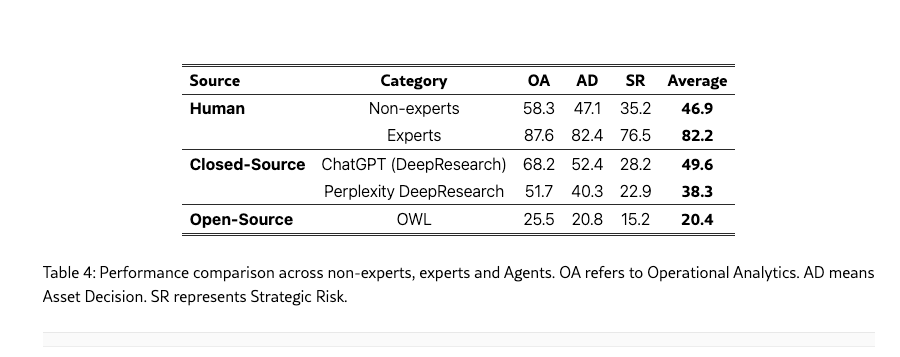
Image source: FinGAIA
In zero-shot settings (when the model is evaluated without task-specific examples, fine-tuning, or additional configuration), the best-performing model reached an overall accuracy of 48.9%. While this exceeded the performance of finance undergraduates, it remained well below that of finance PhDs, underscoring the gap between current LLM capabilities and expert-level financial judgment.
| What the benchmarks suggest | Strong models mentioned | What that means in practice | Notes / limits |
|---|---|---|---|
| Accuracy on complex finance reasoning | GPT-5, GPT-5 mini | Better for multi-step calculations, logic-heavy analysis, and harder analyst-style questions | From AI Multiple (reasoning-focused) |
| Accuracy on finance “agent” tasks | GPT-5.1; Claude Sonnet 4.5 (Thinking) close behind | Better for workflows that combine reasoning + steps like retrieval, light research, and projections | From Vals.AI (agent-style tasks) |
| Cost–accuracy efficiency (tokens vs performance) | Claude Opus 4.1 | Good performance without needing long outputs; can reduce spend in production | Efficiency here is token usage, not pricing |
| Retrieval / grounding reliability | No clear winner; many struggled | Retrieval and tool use are often the failure point; expect to invest in evaluation + guardrails | From Vals.AI + FinanceBench observations |
| Long-document “just put it all in the prompt” | Long context helps but still fails | Feeding entire documents can improve accuracy but may be too slow or costly at scale | From FinanceBench comparisons |
While LLMs can save time on finance work, accuracy is still uneven, especially when the task depends on retrieval, tool use, or multi-step reasoning.
The best-performing models tend to do well on structured reasoning and summarization, but even top models can fail when they have to pull the right evidence, follow a workflow, or operate over long, messy documents. For BFSIs, this shifts the focus from “Which model is best?” to “Which model is best for this workflow, under these controls?”
That’s why model selection and governance need to be designed together. You want the most cost-efficient model that meets your accuracy threshold, wrapped in grounding, access controls, human approval gates, and auditability.
The model you choose will power your AI workflows, automation, agents, or agentic systems. It’s what interprets requests, reasons through problems, and generates responses. This means the wrong choice can have serious implications for cost efficiency, reliability, output quality, and security. Here’s what you need to know when choosing a model:
Different models have different capabilities, so what works for one use case may not be optimal for another. Choosing the wrong model can lead to issues like:
GPT models are not domain-specific financial LLMs. They are general-purpose foundation models trained on broad datasets, meaning they aren’t purpose built to understand financial instruments, firm-specific rules, or regulatory requirements. They also don’t know your internal data, clients, or processes, which means they can hallucinate or produce outputs that are not aligned with your internal standards.
While Custom GPTs let you configure instructions, connect internal documents or a vetted internal knowledge base, and integrate tools to improve consistency and relevance, they do not change the underlying model or eliminate hallucinations. They constrain behavior rather than retrain the model, so outputs still require validation. You still need to ensure strong data governance, cybersecurity controls, and access management.
Although fine-tuning uses additional machine-learning training to improve consistency and task-specific performance, it does not remove base model limitations. Fine-tuned models can still produce incorrect outputs. They can also introduce risk if training data is incomplete or biased. In highly regulated financial services, these models require stronger governance, including model validation, testing and monitoring, documentation, model risk controls, and clear approval pathways.
Models like GPT-5.1 and GPT-4.1 can accelerate compliance tasks by summarizing financial statements, extracting key points, reviewing content, and drafting regulatory materials.
However, they can’t replace formal controls or be allowed to function as a black box. To remain compliant, you still need transparent documented rules, clear financial decision logic aligned with CFO oversight, structured approval flows, human oversight, and audit trails.
Strict compliance requirements around AI data security and privacy mean you’ll need to be able to defend your model to regulators.
You must be able to explain how your chosen model works, what data it can access, how you test it, and how you monitor it to ensure reliability.
Regulators will expect you to have strong governance, transparency, testing protocols, auditability, bias checks, fallback plans, and clear boundaries around model capability and risk.
An in-house approach can work for low-risk, standalone tasks, such as drafting internal content or summarizing documents, where you don’t need to train or fine-tune a model on your own data.
But for more complex financial use cases, even just generating market insights to personalize client investment proposals requires evidence. This includes how the model performs on your real-world documents, its reliability in following tools and controls, what it costs at scale, and how you will defend it to auditors and regulators.
A consultancy can help with selecting a model by running a structured evaluation and translating results into a model choice you can justify. It can then support implementation by integrating the model with your systems, establishing governance frameworks, and applying prompt engineering for reliable, accurate outputs.
You’ll find that turning to an external partner for help is more effective if:
Even if you have the in-house capability to choose and integrate models, you can still benefit from external support. For example, external specialists can help validate and compare model options, assess trade-offs around accuracy, AI cost, and risk management. They can also deliver quick results while your internal team stays focused on its core work.
If you choose this route, the next step is selecting an AI enablement partner that can support you in meeting your regulatory, operational, and strategic goals.
Neurons Lab is an AWS Advanced Tier partner with proven expertise in Generative AI and Financial Services. As both a systems integrator and consultancy, we help firms overcome the limitations of off-the-shelf AI tools with compliant, tailored solutions that deliver measurable results and clear metrics.
We’ve delivered such solutions to leading financial institutions, including Visa, AXA, and SMFG. Here’s how you’ll benefit from choosing us to select and integrate your large language model:
By partnering with our AI-exclusive consulting firm, you’ll have the hands-on support you need across the entire AI lifecycle. This means you’ll have help whether it’s choosing the right model, setting up an AI strategy and roadmap, building PoCs, or deploying and scaling production-grade solutions.

Neurons Lab’s end-to-end AI development and consultancy services
Our co-innovation approach also ensures that you can build your own AI development team or train your existing teams. Your teams will learn AI agent evaluation frameworks (AI evals), prompt engineering, and other essential skills to work confidently with AI through our workshops and practical resources. This ensures you develop internal capability that prevents vendor lock-in, empowering your firm for long-term success.
On their own, GPTs struggle to reliably handle complex workflows without proper grounding, tool access, and governance. This often leads to generic or inconsistent outputs and higher compliance risk, particularly when models are not connected to authoritative internal data or controlled systems with auditability and human oversight in place.
As a systems integrator with deep financial services expertise, we understand both FSI workflows and the industry’s complex regulatory landscape. This means you’ll be able to adapt your AI models for use cases, such as insights generation for financial analysts, automated market trend analysis for portfolio managers, or a copilot for finance teams or relationship managers.
From building retrieval systems on your proprietary data to fine-tuning models for specialized tasks and designing role-specific workflows with agents, guardrails, and prompts, you’ll have expert support throughout.
You can also be confident your custom AI business solutions are backed by governance frameworks, prompt engineering best practices, and data foundations aligned with regulatory standards, such as GDPR, OCC, MAS, and ISO/IEC 27001, making them deployable at scale.
For example, if you’re a wealth management firm, you can create a single conversational interface for your relationship managers that uses your GPT model together with a custom agentic AI system to pull from internal systems, market data, and compliance-approved sources. Instead of consulting multiple sources, your finance professionals can simply prompt this system to receive instant, source-backed insights that would otherwise take hours of manual research.
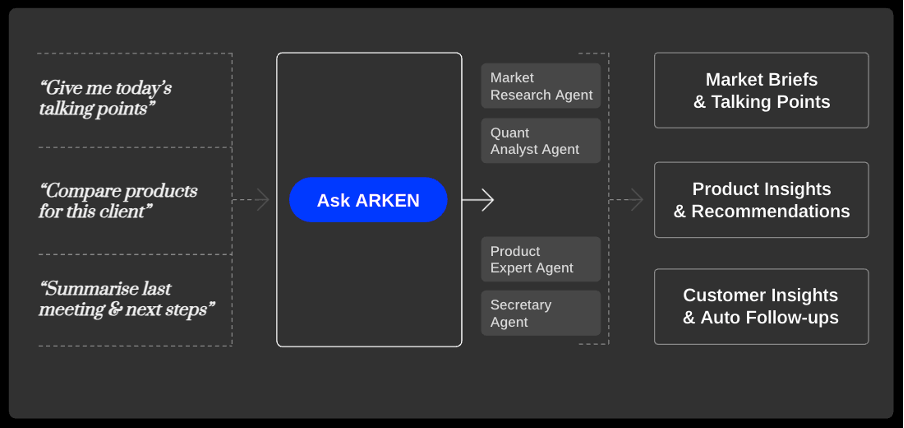
Caption: Neurons Lab’s ARKEN transforms simple prompts into market briefs, product insights, and client follow-ups, enabling more personalized recommendations
A large Asian bank is currently using a solution like this, powered by ARKEN, our wealth management AI accelerator. The results include 30% more client capacity per wealth manager without adding headcount, more consistent client engagement, and improved NPS scores of 15 to 20%.
With our global network of 500+ engineers with expertise in RAG, orchestration, multi-agent systems, and MLOps, you’ll be able to deploy your model quickly without compromising accuracy, security, or compliance.
Our boutique structure further enables faster decision-making and delivery of AI integration paths and unified data foundations. And by using customizable accelerator solutions built on tested code, reusable components, and pre-built integration and reasoning layers, you’ll be able to adapt out-of-the-box GPT models to your systems and go to production in 2 to 4 months.
Model choice is critical for performance, cost efficiency, compliance, and long-term scalability. As we’ve covered, the best model depends entirely on your use case: simple workflows may need lightweight models, while complex tasks, multi-agent systems, or long-document analysis require more powerful GPT models with larger context windows and stronger reasoning.
Whatever provider you choose, your model must meet strict requirements around data privacy, security, auditability, and regulatory compliance. Beyond choosing a model, there’s still the complexity of governance, testing, monitoring, and ensuring an AI-driven solution aligns with your systems and fits your existing workflows.
That’s why working with an experienced AI and financial services enablement partner can set you up for success. The right partner understands the FSI regulatory environment, designs compliance into the solution from day one, and knows how to test, build, and deploy LLM-powered systems that are secure, compliant, and work as intended.
If you want to move beyond the limitations of out-of-the-box models and build compliant custom AI solutions that meet your unique needs and drive measurable results, contact us today.
LLMs like OpenAI’s series 5 model generate responses by predicting the next piece of text based on patterns they learned during training. For example, in finance, GPT 5.1 might generate a summary of a quarterly earnings report or draft an investment commentary by identifying and reproducing patterns common in financial reports and market analysis.
There isn’t a separate large language model specific to finance or available as a standalone product; there are finance-focused versions and applications, such as BloombergGPT or Claude for Financial Services.
No, a model can’t access or learn from your private financial data unless you grant it access to your private data or intentionally fine-tune it based on your own training data set. With pro-level accounts in LLM tools like Claude or ChatGPT, your data is protected by enterprise-grade privacy, access controls, and governance, and is not shared or used to retrain base models.
Sources:
Learn how retail banks use AI agents to automate workflows, improve customer experience, and scale operations with measurable results.
AI strategy consulting for financial services: compare top firms, key selection criteria, and how to move from pilots to production-ready AI systems.
Agentic AI in banking helps banks automate workflows, improve customer service, reduce costs, and scale secure AI across divisions.
AI in capital markets helps firms scale operations, automate workflows, and act on real-time data to improve performance and reduce risk.
Microsoft Copilot for Finance delivers strong out-of-the-box gains, but requires customization to handle complex, regulated financial workflows.



