

Security in large language models (LLMs) is crucial and early adoption of the right safety measures is important to protect AI models, as it is with any other advanced form of technology.
The signs are there that while many employees are already embracing the benefits that generative AI can bring, some of the companies they work for are more hesitant and cautious, waiting a little longer before making their move.
A recent McKinsey Global Survey found that employees are far ahead of their companies in using GenAI overall, with only 13% of businesses falling into the early adopter category. Of these early adopters, nearly half of their staff – 43% – are heavy users of GenAI.
Moreover, the IBM Institute for Business Value found that 64% of CEOs are receiving significant pressure from investors to accelerate their adoption of GenAI. But most – 60% – are not yet implementing a consistent, enterprise-wide approach to achieve this.
Why? One key reason appears to be due to considerations around ensuring security, with more IBM data showing that 84% are worried about the risks of any GenAI-related cybersecurity attacks.
In this article, Part 1, we will cover some of the most common potential types of attacks on LLMs, then explain how to mitigate the risks with security measures and safety-first principles.
In the next article, Part 2, we will explore advanced attack techniques against LLMs in detail, then run through how to mitigate these risks using external guardrails and safety procedures.
Main attack types on LLMs
Research from Security Intelligence has evaluated the potential impact of six main attack types on GenAI, alongside how challenging it is for attackers to execute them:
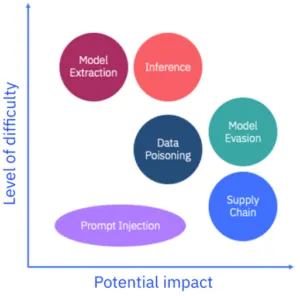
- Prompt injection: The user manipulates an LLM with malicious inputs capable of ‘tricking’ it and overriding guardrails that the developer put in place. This is similar to ‘jailbreaking’ and most LLMs have measures in place to anticipate and prevent this relatively basic attack.
- Model extraction: Through extensive queries and monitoring the outputs, the user tries to steal the model’s behavior and IP. This is a very difficult attack to execute, requiring vast knowledge and resources.
- Data poisoning: This is the tampering of data involved in training an AI model to change its behavior or insert vulnerabilities. It is easier to achieve with open-source models but with closed data sets, only a malicious insider or person with the right level of access could execute this attack.
- Inference: The user aims to infer sensitive information based on partial information from training data. A relatively difficult attack to execute, prevention measures include using differential privacy and adversarial training.
- Supply chain: These attacks target other software and technologies connected to the AI model that potentially do not have the same level of protection as the LLM. A supply chain attack requires significant, sophisticated knowledge of the connected architecture.
- Model evasion: The user aims to deceive the LLM by modifying inputs in a way that the AI model could misinterpret them and then behave illogically.
There are more types of attack to prepare for though.
OWASP Top 10 examples
For a more comprehensive list of threats facing LLMs, the Open Web Application Security Project (OWASP) is a valuable resource. OWASP provides guidelines to help risk management and data security experts prepare for a wide range of different potential technological vulnerabilities.
OWASP’s Top 10 is particularly useful as it provides a hierarchy of the biggest security risks, updated every few years to capture any growing threats.
In this table, cybersecurity experts Lasso detail the OWASP Top 10 potential vulnerabilities for LLMs and different ways to prevent them.
Proactive measures that can help to secure LLMs include regularly auditing user activity logs, with strong access controls and authentication procedures also in place.
Developers need to fine-tune bespoke LLMs for improved accuracy and security before launch. They also need to put measures in place to clean and validate input data before it enters the LLM’s system.
Key principles – defending against LLM attacks
In an AWS Machine Learning blog post, Harel Gal et al outline how AI model producers and the companies that leverage them must work together to ensure that appropriate safety mechanisms are in place.
Responsibility lies with AI model producers to:
- Pre-process data: Clean any open-source data before using it to train an LLM base model
- Share model cards: Provide transparent detail behind the model development process. For example, here is the publicly available model card for Anthropic’s Claude 3.
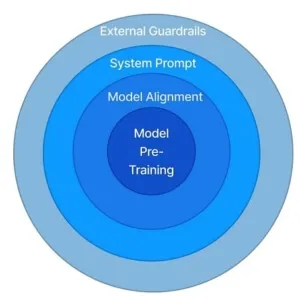
- Align the model to security values: In the next section, we’ll run through how we ensure our AI solutions adhere to our standards around data privacy, safety, IP, and veracity.
Companies deploying LLMs also have a responsibility to ensure that they or their provider have put key security measures in place.
In addition to creating blueprint system prompt template inputs and outputs, these measures include:
- Specifying the tone
- Fine-tuning the model
- Adding external guardrails
We will share more details on these approaches shortly.
Applying these safety mechanisms creates layers of security for LLMs:
AWS Security Reference Architecture and guardrails: Overview
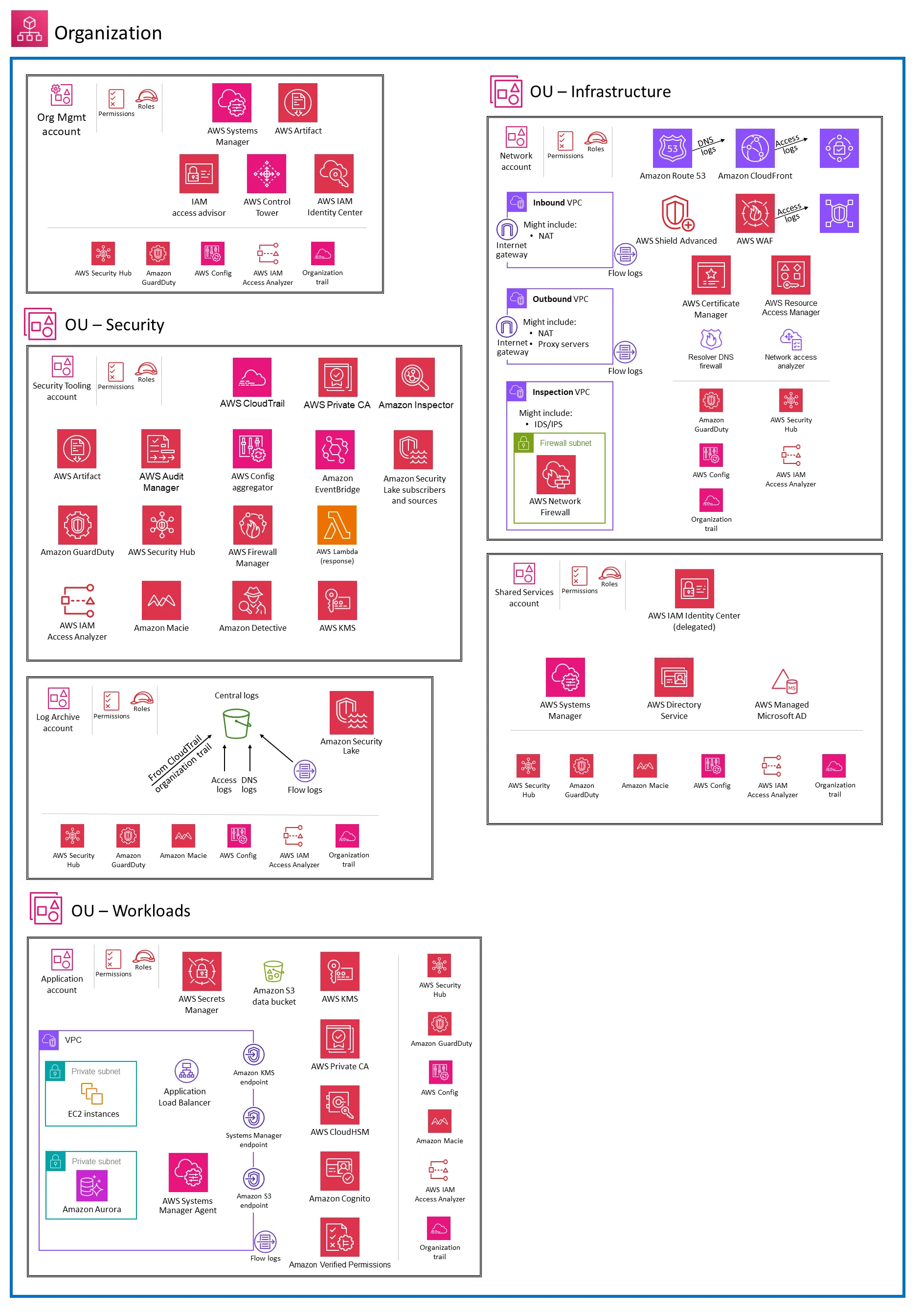
Amazon Web Services (AWS) has a wide range of security-related applications well suited to business infrastructure. For context, the below diagram shows the AWS Security Reference Architecture (SRA).
There are three tiers in the SRA workload:
- Web tier: Users connect and interact through this interface part of the architecture
- Application tier: This handles user inputs, analyzes them, and creates the outputs
- Data tier: The application tier stores and retrieves information from this part of the architecture
From the below diagram, selected highlights include:
- AWS Secrets Manager – to securely manage sensitive data
- AWS Artifact – to access compliance reports and agreements
- Key Management Service (KMS) – for encryption and secure key management
We’ll explore several external guardrails for GenAI applications comprehensively in Part 2 of this article, summarizing key insights from the aforementioned AWS Machine Learning blog post from Harel Gal et al.
These include Amazon Bedrock and Comprehend.
How we ensure security in AI projects
Here at Neurons Lab we follow a comprehensive security framework that covers all bases for successful and secure AI projects. Informed by clients’ priorities around safety, these are some of the highlights:

Veracity
- RAG and Agentic Architectures empowered by Knowledge Graphs
- Customizing AI models via prompting, fine-tuning and training from scratch
Toxicity & safety
- Built-in Guardrails in Amazon Bedrock & Amazon Q
- Model evaluation in Amazon Bedrock & SageMaker Clarify
Intellectual property
- Uncapped IP indemnity coverage for Amazon Titan
- Copyright indemnity for Anthropic models in Amazon Bedrock
Data privacy & security
- Your data is not used to train the base models
- VPC access to the GenAI services and custom fine-tuned models
- Customer-managed keys to encrypt your data
In the next article – Part 2, coming soon – we will explore advanced attack techniques against LLMs in detail, then explain how to mitigate these risks using external guardrails and safety procedures.
About us: Neurons Lab
Neurons Lab delivers AI transformation services to guide enterprises into the new era of AI. Our approach covers the complete AI spectrum, combining leadership alignment with technology integration to deliver measurable outcomes.
As an AWS Advanced Partner and GenAI competency holder, we have successfully delivered tailored AI solutions to over 100 clients, including Fortune 500 companies and governmental organizations.




