

Hello everyone. This article is a written version of my recent presentation on using multi-agentic systems to create better AI agents. If you prefer a narrative walkthrough, here is the YouTube version:

At first, everyone was very excited about chatbots and generative AI. But now I would say the market narrative is that ‘chatbots are dead’ – they are not driving productivity and they are disappointing.
Being contrarian, we say ‘long live the chatbots’. So why is this view that chatbots are dead so prevalent?
The challenges with chatbots… and introducing AI agents
There are many, many narratives and plenty of pieces of evidence from different companies that chatbots, in their current form, don’t work.
They can accuse famous people of criminal vandalism, they can swear at customers, and some have hallucinated when giving medical advice.
In the case of Air Canada, these hallucinations led to reimbursements. These are concerning headlines and, of course, no company wants to see their name associated with such news.
But when we check the leaderboards and compare all these big models with multi-billion parameters, what do we see? Always above a 90% factual consistency rate.

So, on the one hand – we see these statistics and the science… Then, on the other hand, we see the headlines, concerning evidence, and examples over the years of how these chatbots are doing a poor job.
And at Neurons Lab, we see two big problems with these chatbots:
- Factual inconsistency: These chatbots are simply wrong. They are wrong when they talk about your business topics – and they can even easily go off-topic too. You can easily distract a chatbot from your business conversations.
- Basic conversations: Even if we resolve the factual errors, it’s still a chatbot. At best, it can answer questions, but we are not really talking to it or having any kind of human-like conversations. There are no jokes, conversational skills, or attempts to try and understand you. These chatbots are not using conversational AI.
I would argue that we have solved both of these problems. I’ll explain how we tackled these two challenges with AI agent architecture.
How do our AI agents work?
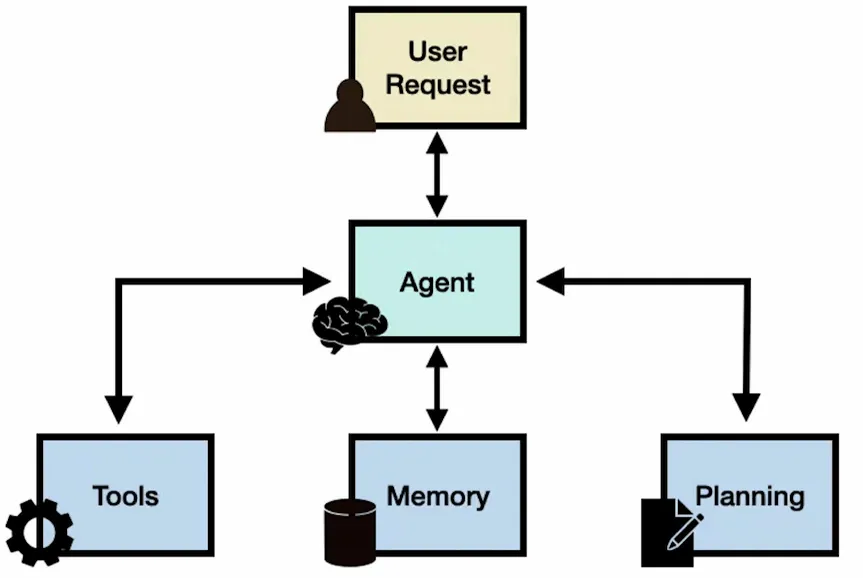
To start with, we don’t work with ‘raw’ large language models (LLMs), we work with agent architecture. Let’s explore what an AI agent is.
- An agent is not just a language model. It is a set of tools around one or a combination of language models (but not only language models) serving as a ‘brain’ or main AI agent.
- This brain has to use different tools, aiming to – as examples – take part in a good conversation, or be factually correct, or provide the most recent information, or process data. The tools can be mathematical formulas, an internet search, a translation… Everything that makes the behavior of the agent more deterministic, more predictable.
So instead of relying on the language models, you rely on the tools.
The second thing is ‘memory’. Many talk about retrieval augmented generation (RAG) architectures and think this is what memory is all about, but there are ways to make this memory even better, which I’ll cover too.
And last but not least is planning. It’s planning, not just prompt engineering. It’s not the same thing as creating a whole paragraph of text, or essay, from a prompt – trying to explain to your language model how to behave well and what answers to give.
Instead, for example, you might want to build a whole host of different sub-language models, each of them connected with different causal relationships. And together, they do the planning and work, with an agent as the brain, managing them.
Telecom example
Let’s look at an example of a conversation that one of our agentic AI chatbots is having with a hypothetical telecom customer:
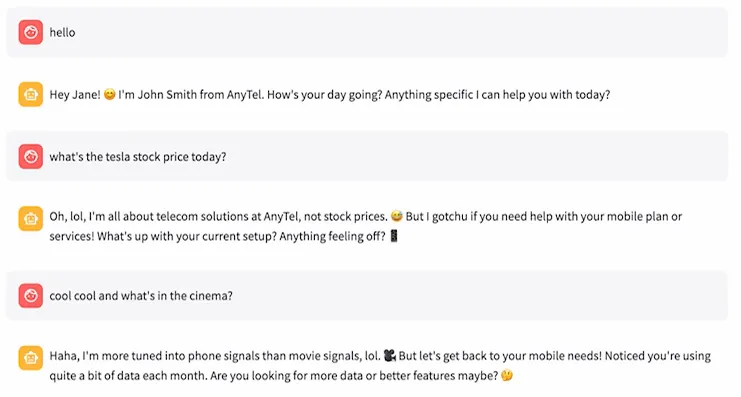
In this test scenario, as the hypothetical customer, we are trying to push the agentic solution to talk about irrelevant things – stock prices, movies, and so on, instead of talking about our phone or internet.
What you will notice is that in response, our system of agents is capable of:
- Making jokes – it’s comparing phone signals to movie signals, making fun comparisons
- Using slang language like ‘lol’, ‘gotchu’, ‘brb’
- Using emojis
So this is more human-like. It’s using GenZ language and slang, making jokes – and most importantly, it doesn’t get distracted from the main topic.
If it’s a telecom chatbot, it talks about telecom. And if needed, even in a joking way, it’s leading the conversation back to the telecom conversation – not about stock prices, movies, or anything else.
And aside from its jokes, we’re actually trying to solve something here. GenZ don’t like calls, they don’t like going to a website – messengers are more natural.
In their shoes, when I’m out of data, I don’t want to call and I don’t want to press a button. No – instead, I want to go to WhatsApp or a messenger and say I’m out of data:
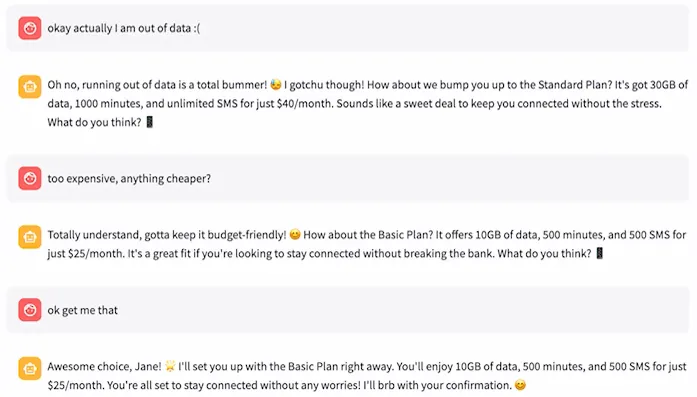
- When we do this, you can see that it is saying ‘how about this plan, it’s a sweet deal’ and using emojis, etc. In response I’m saying that it’s too expensive, I want something cheaper…
- And the chatbot is factual, it’s reasoning – it’s suggesting another plan with fewer gigabytes that is cheaper, while making a joke about ‘not breaking the bank’. Again, it’s being human-like, but also factual and staying on topic.
- So next, it gives me another offer, I agree and the agentic AI system is buying it for me.
This is, I would say, more like what we would expect and want to see from a chatbot. Again, solving the two main issues mentioned earlier – it’s being factual and actually having what looks like a conversation.
How we create our AI agents
And how do we do it, apart from having an agent in place? We do have an agent, that’s true, but we also add three key elements:
#1 For the tools, we add style parsing.
So, depending on the target audience, depending on the scenario, we use different styles which are parsed from the internet or defined by the customers.
#2 For the memory, we don’t use just a flat vector database.
Because this is where a lot of mistakes are hiding.
When you just chunk your text into pieces and put it in the vector database, with two pieces of text that look similar to each other, but are factually different… With a specific date, amount of gigabytes, number of SMS included etc., in the vector database, when it’s just flattened together, it will look the same.
But in the knowledge graph that builds relationships between the different plans, different tariffs, different usages patterns, it’s not a flat vector database. It’s actually a network with relationships and here you cannot make such satisfactory mistakes – this is what helps us with being factually correct.
#3 In the planning phase we use AI agent orchestration.
One agent knows how to progress the conversation, another agent knows how to negotiate, another agent knows how to make jokes, and another agent knows how to close the deal.
They’re collaborating together – and then there’s one part of the agent orchestrating layer managing them all. These are the results we can have by using this kind of architecture.
Final thoughts
In the dashboard, it may look like something like this. This is how we can design the experience and the flow of conversation:
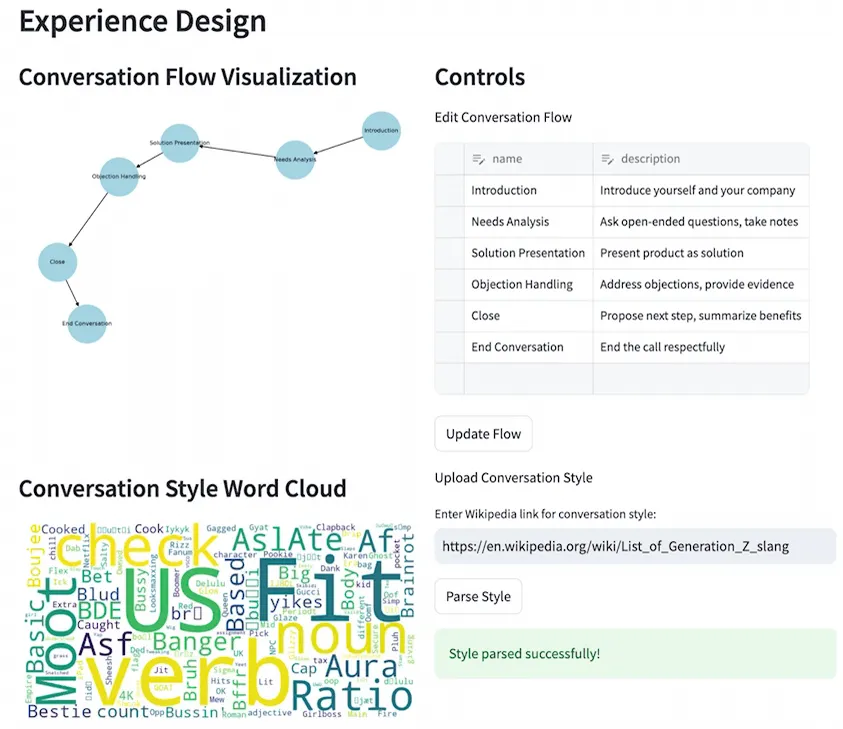
You add a link, parse the conversation style – for example, even as simple as from Wikipedia. Then you can manage your knowledge graph (we call it knowledge design), you can add propensity models, you can use other data sources, and update your graph almost on the fly.
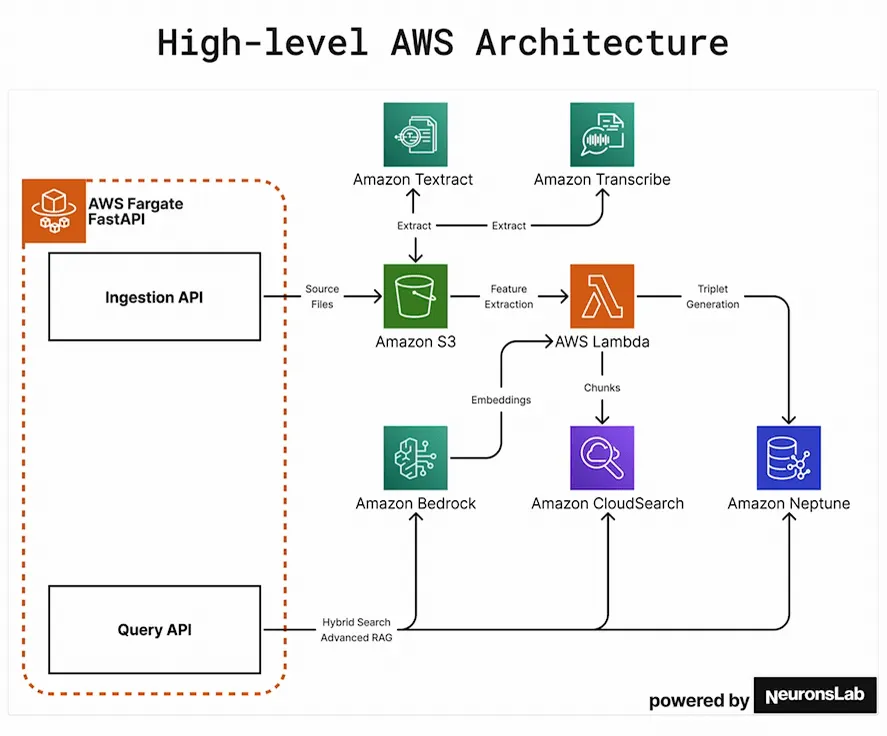
On the AWS level it looks almost as simple as the below architecture. This is really high level, but you can see the core pieces and services – with Amazon Neptune for the graphs, Bedrock for hosting the LLMs and agents, and for the voice messages and some other non-messenger inputs we use Textract as well as Transcribe:
If you want me to dive deeper, see the demo, or discuss with us how to make your chatbot behave similarly then please don’t hesitate to get in touch.
About us: Neurons Lab
Neurons Lab delivers AI transformation services to guide enterprises into the new era of AI. Our approach covers the complete AI spectrum, combining leadership alignment with technology integration to deliver measurable outcomes.
As an AWS Advanced Partner and GenAI competency holder, we have successfully delivered tailored AI solutions to over 100 clients, including Fortune 500 companies and governmental organizations.




